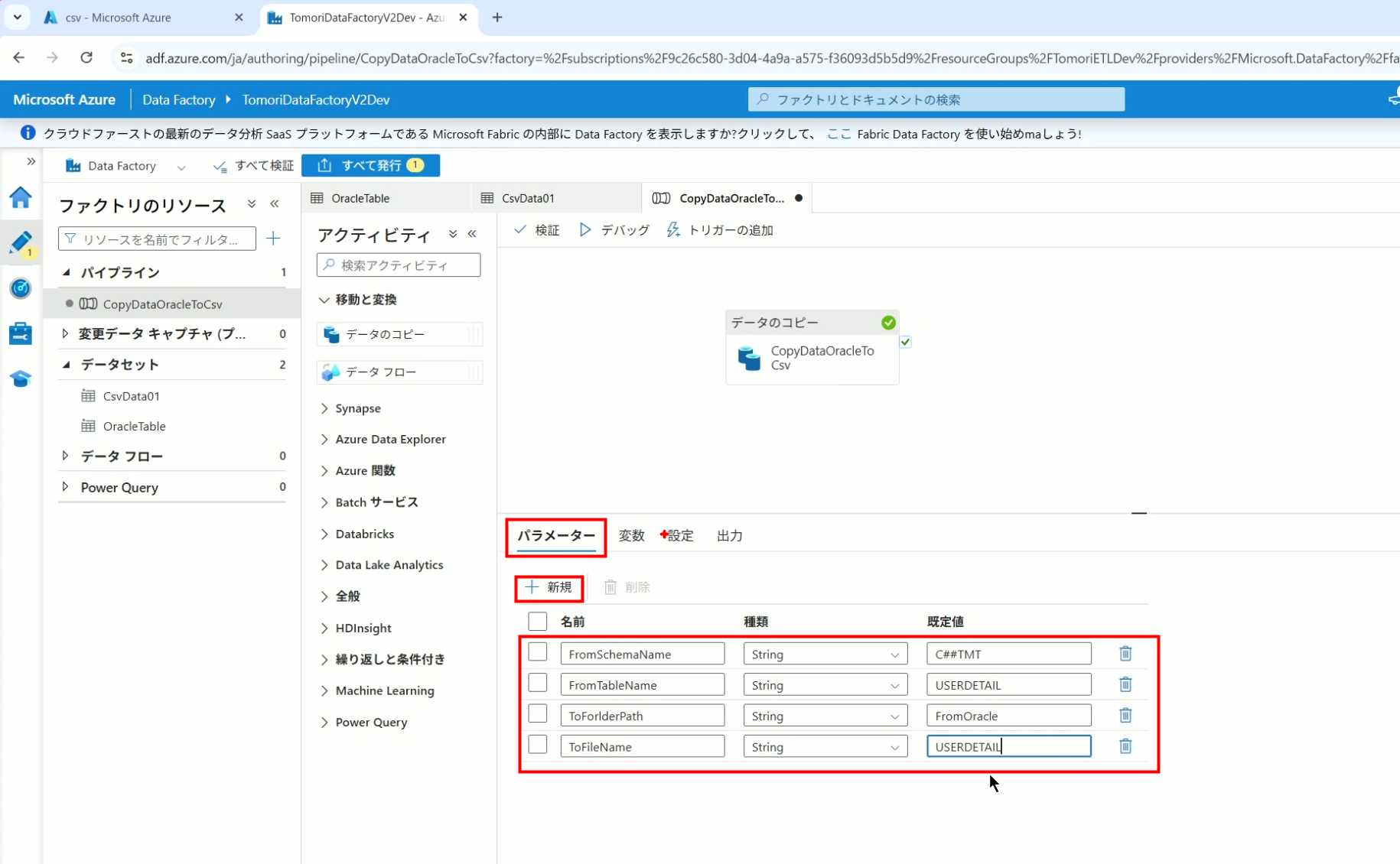
1、我们可以在Pipeline的参数中添加参数,以及设置参数的初始值,这样就可以通过参数来动态控制从哪个表获取数据,将数据保存成什么文件
2、Oracle的Dataset中也添加参数
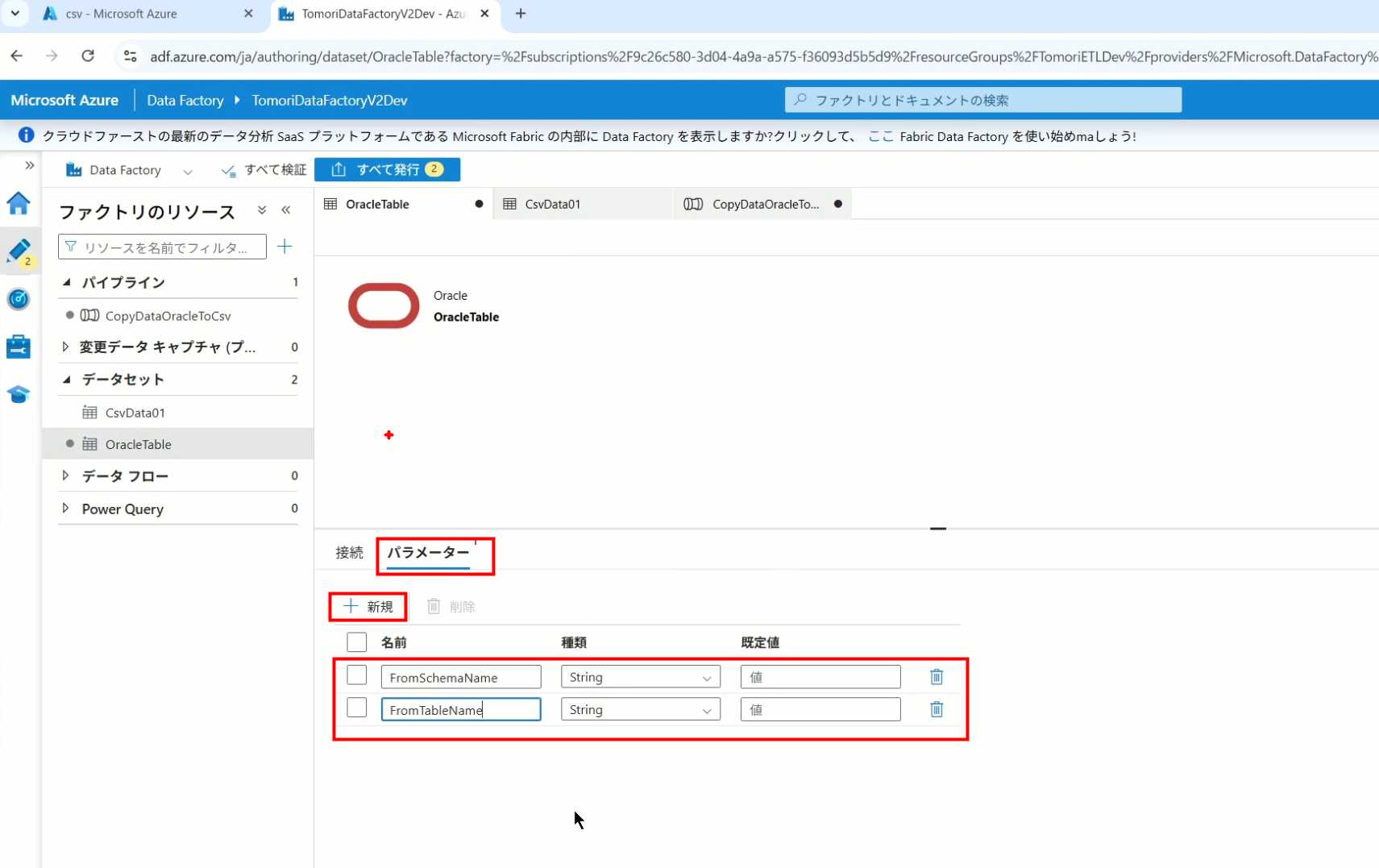
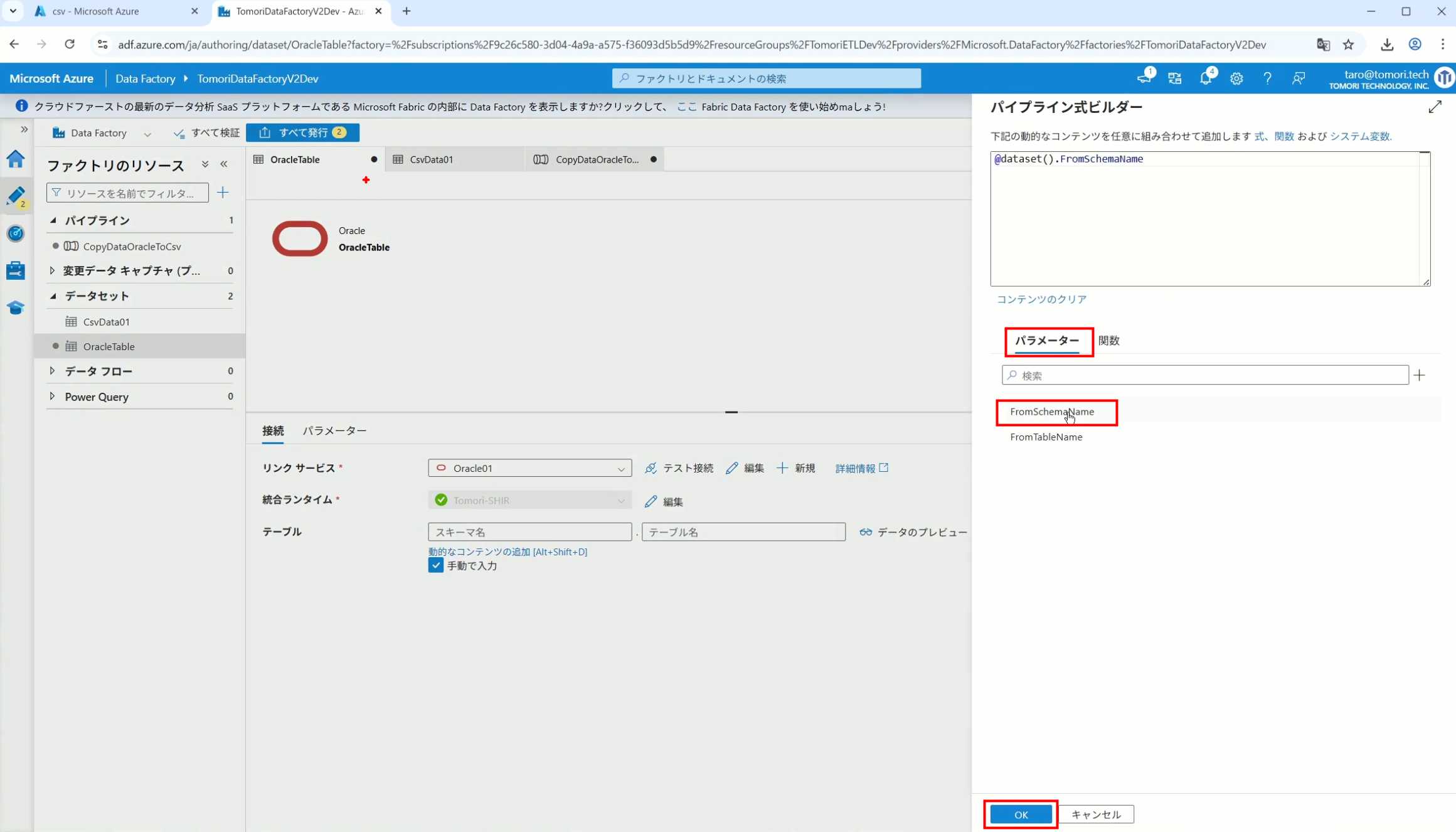
3、Dataset中的Schema名和表名改用参数
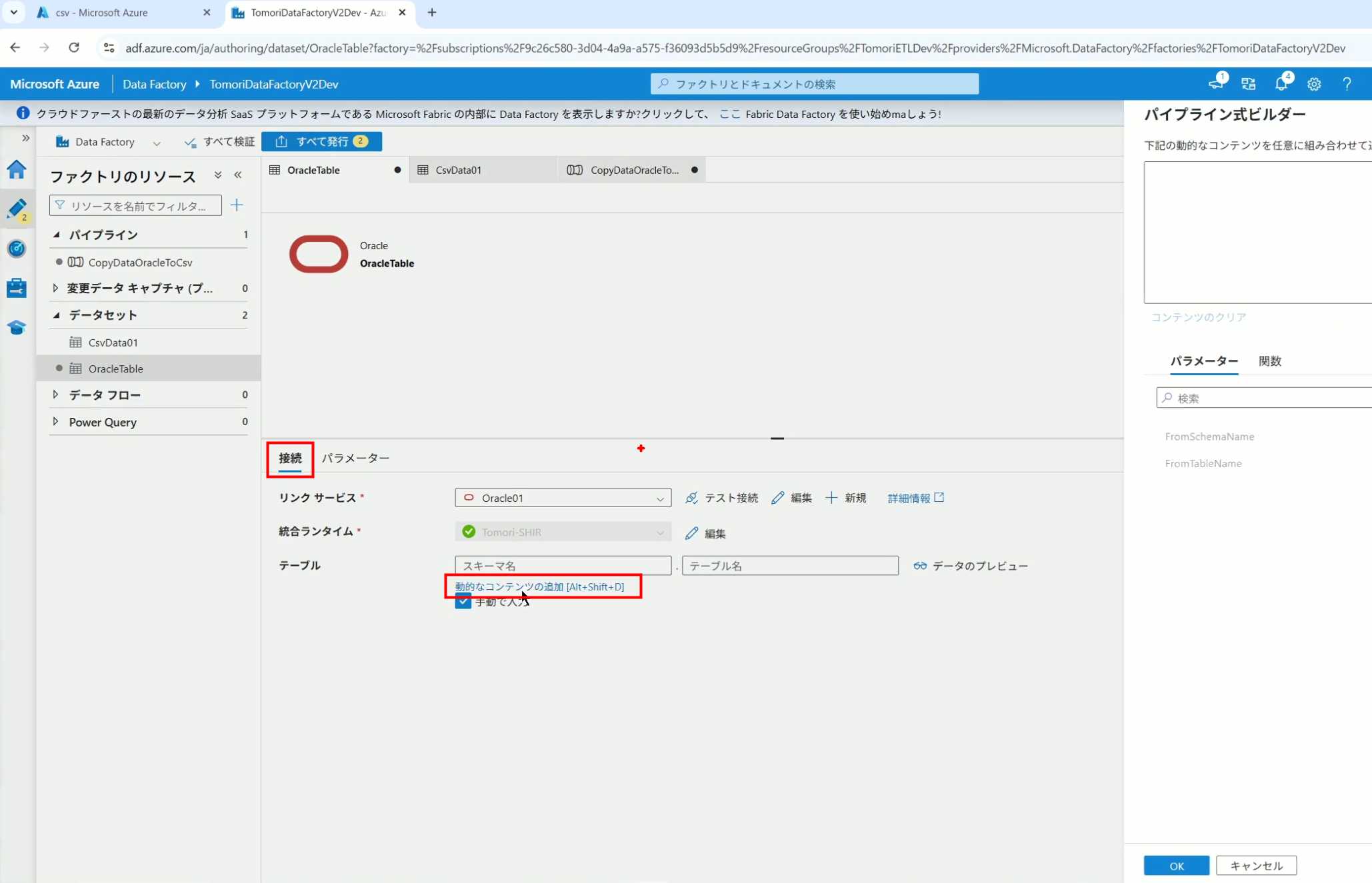
4、点击参数即可使用(参数会跳到上面的编辑栏里)
5、同样,Storage的Dataset里也添加参数
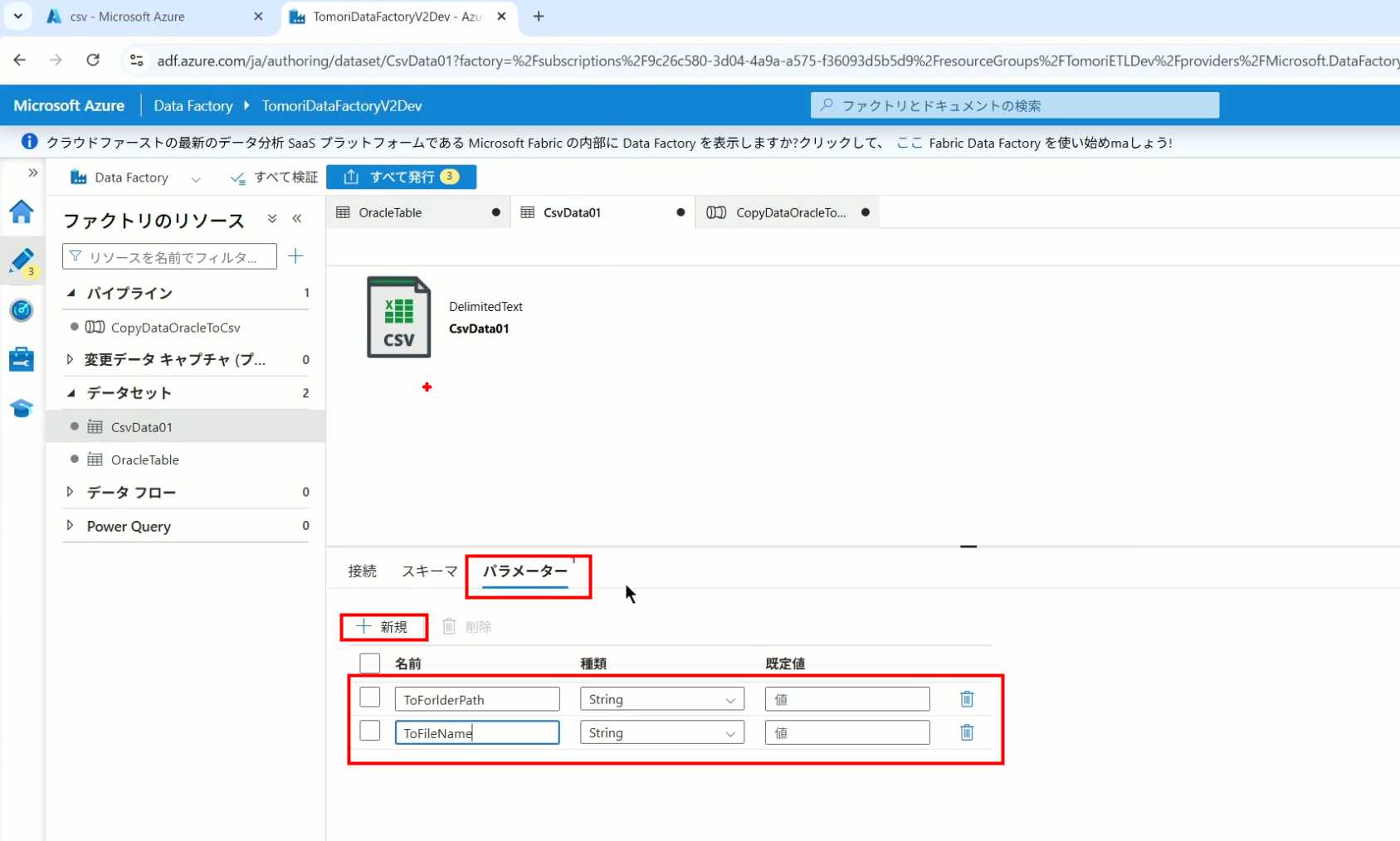
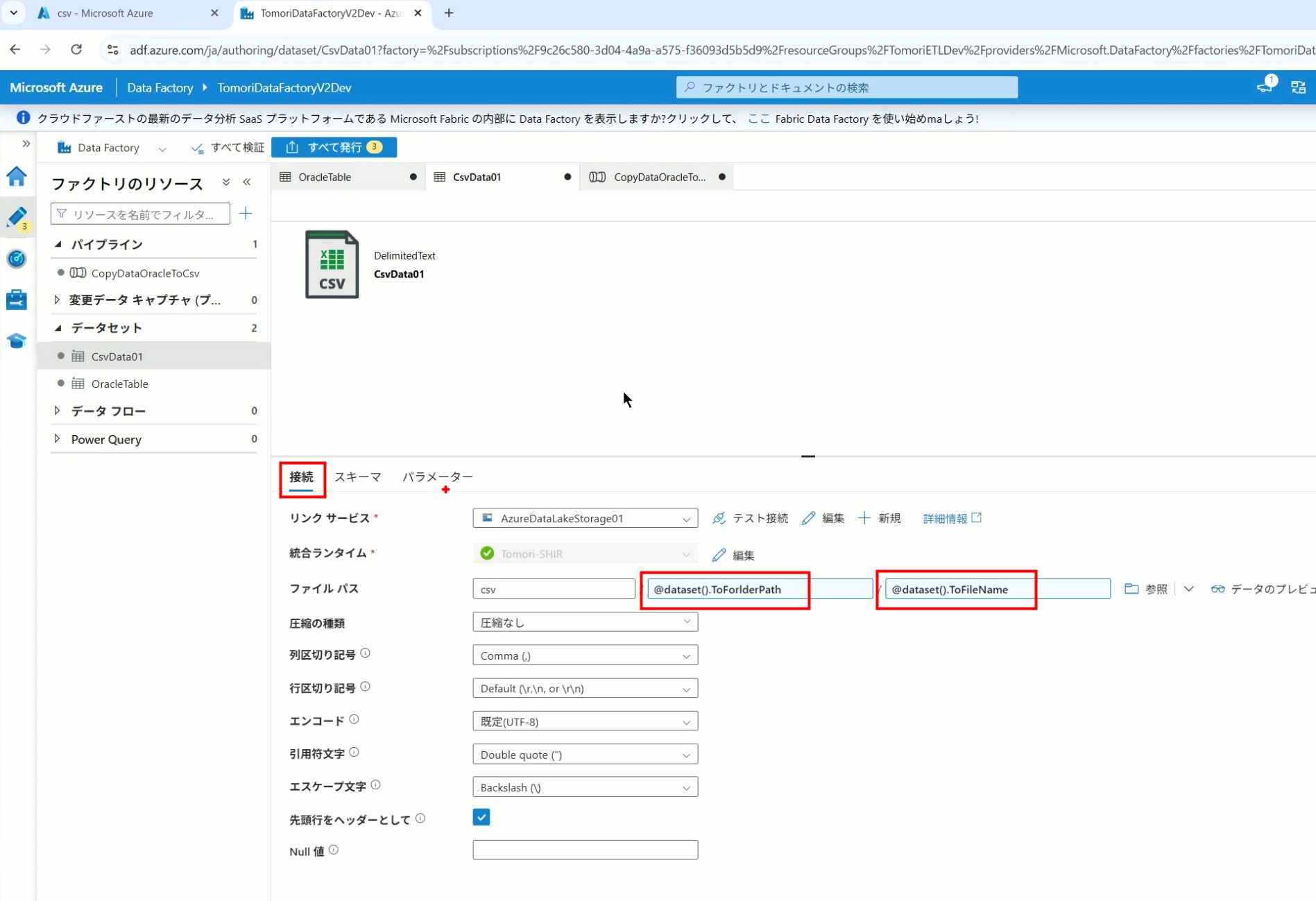
6、保存文件的路径,文件名都设置为使用参数
7、在Copy Activity的Source里,将Pipeline的参数传递给Oracle的Dataset
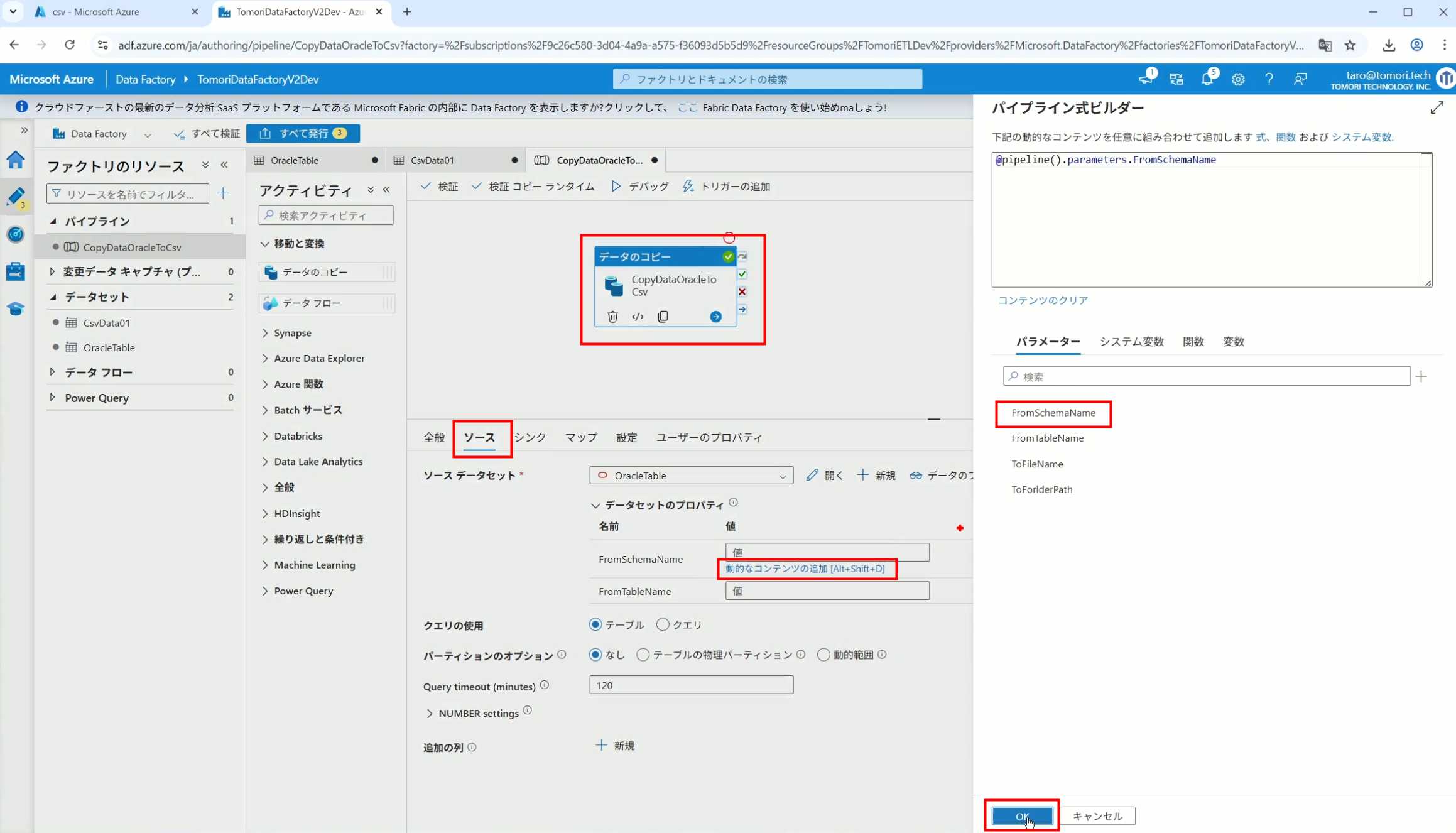
8、设置好的样子
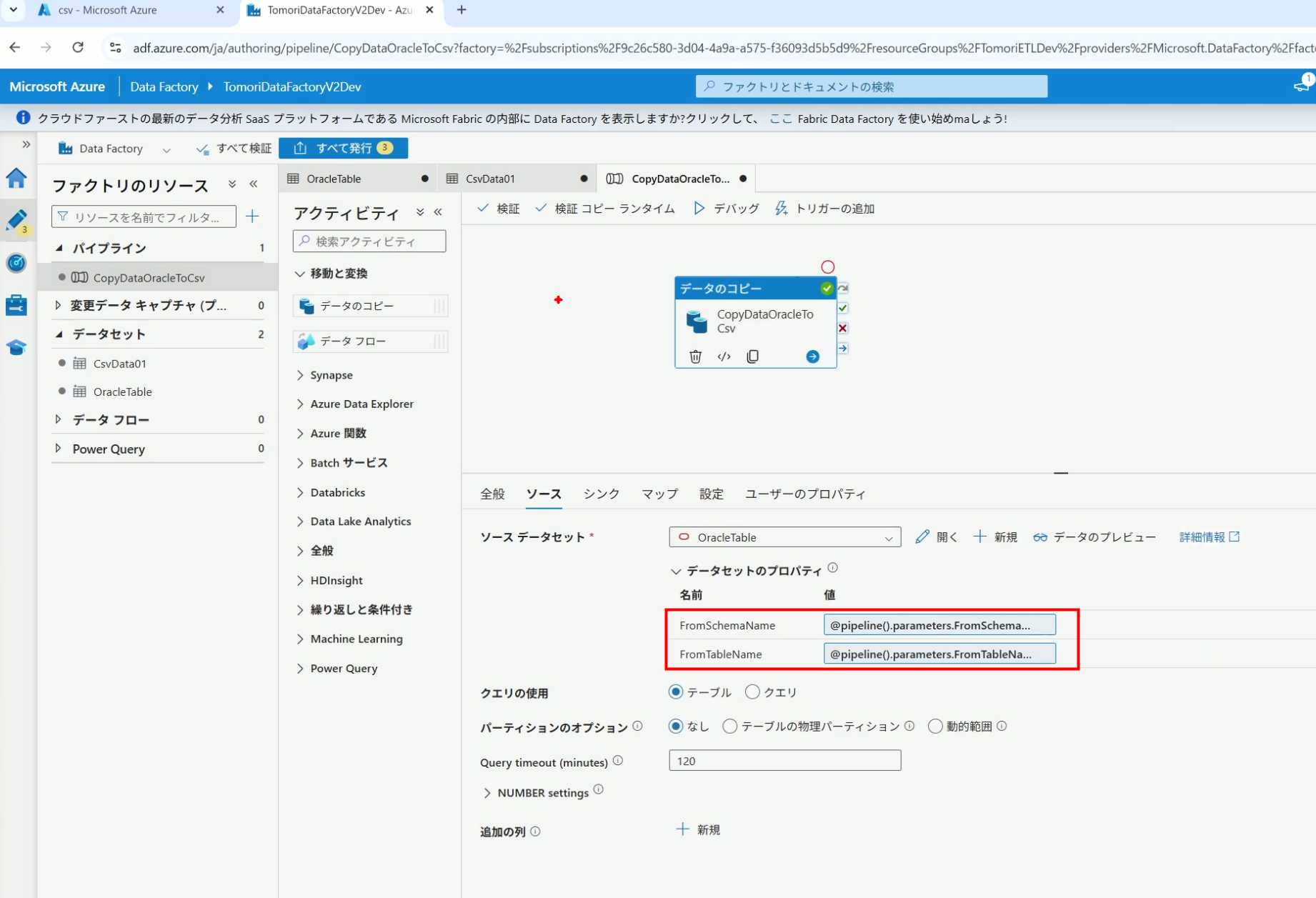
9、在Copy Activity的Sink中,将Pipeline的参数传递给Storage的Dataset
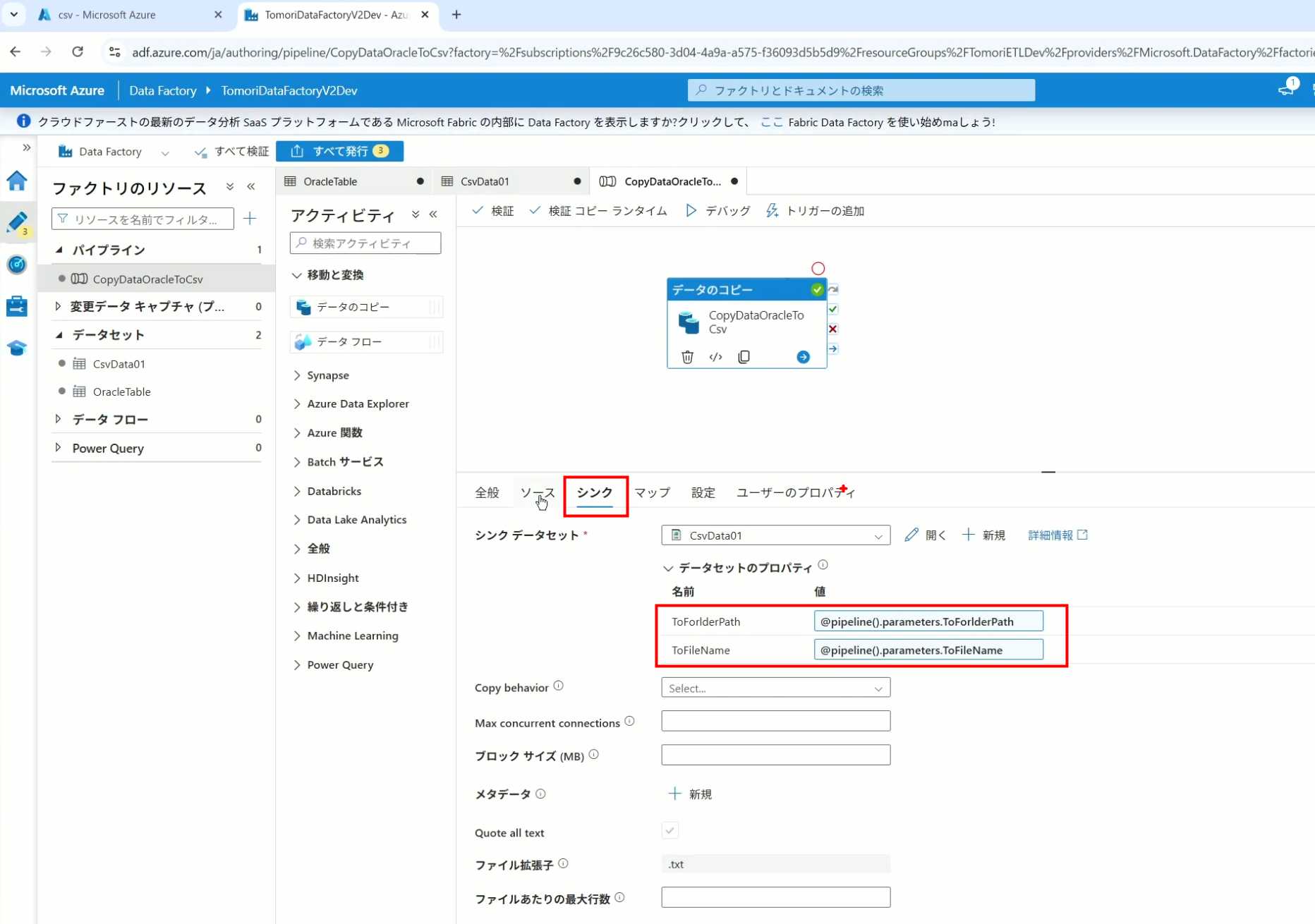
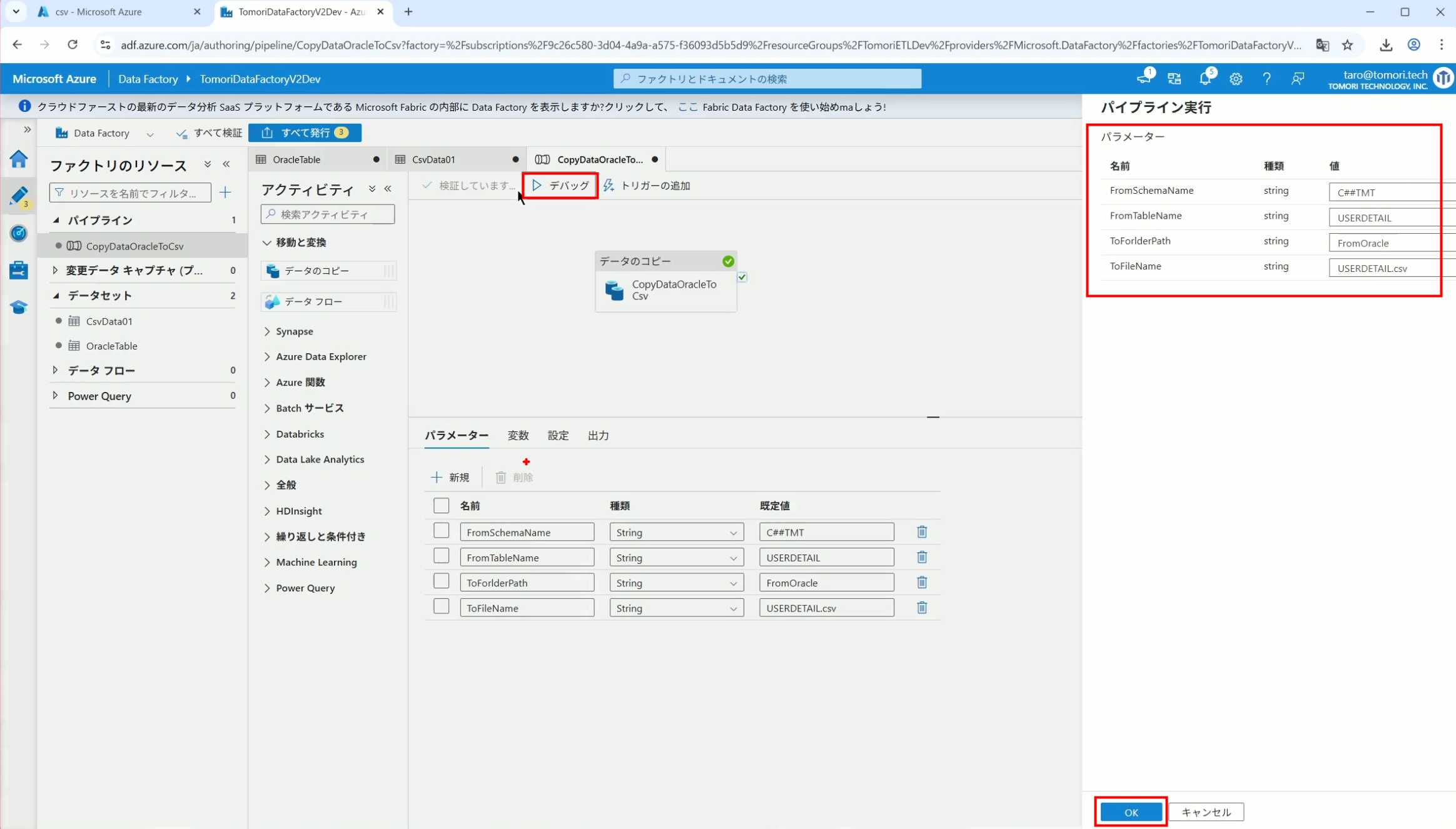
10、再以Debug模式运行Pipeline,这时就会出现参数框,因为我们设置了默认值,所以在里不需要再设置,如果没有设置默认值,可以在这里填入参数值
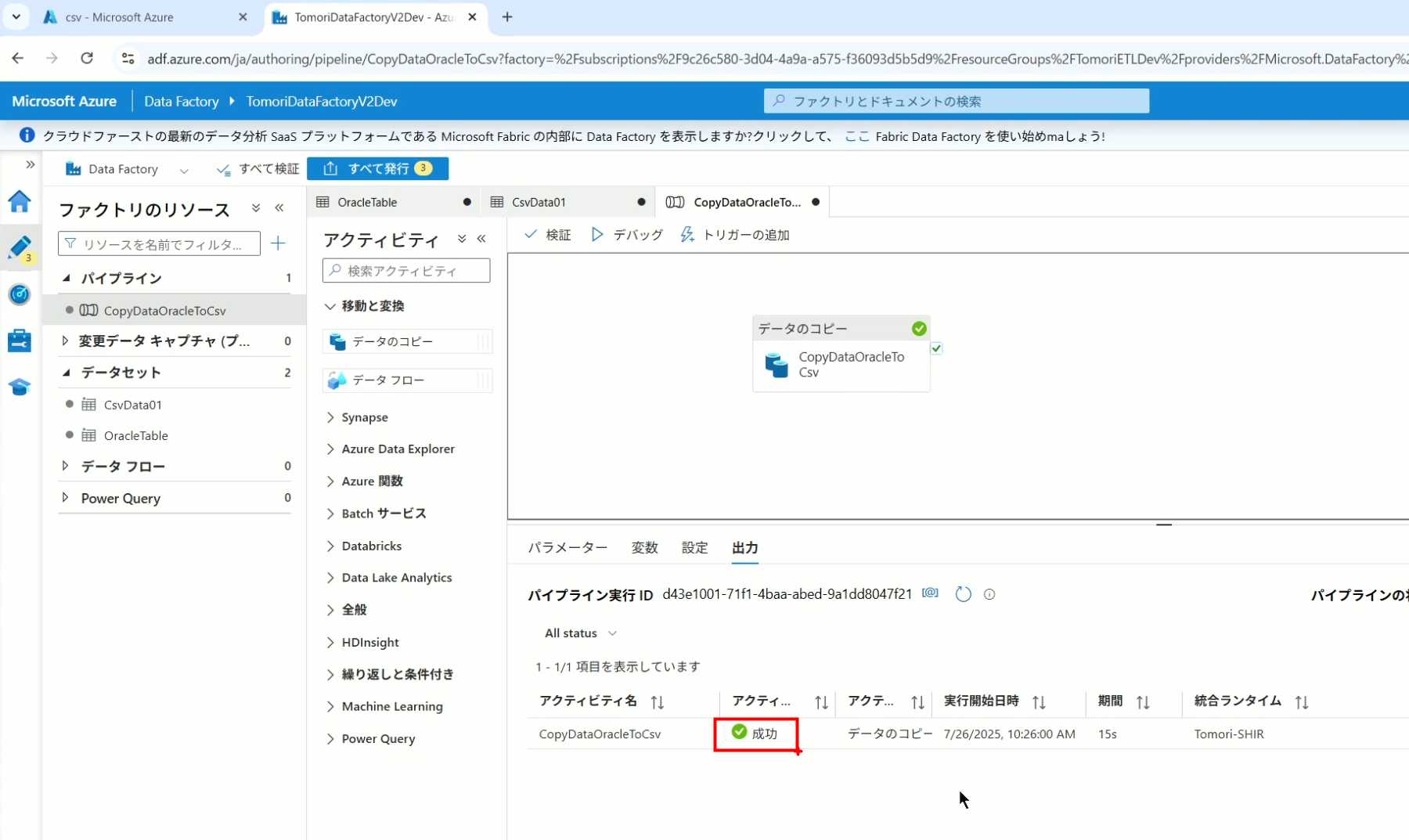
11、查看运行结果(成功)
12、修改默认参数值,再次运行
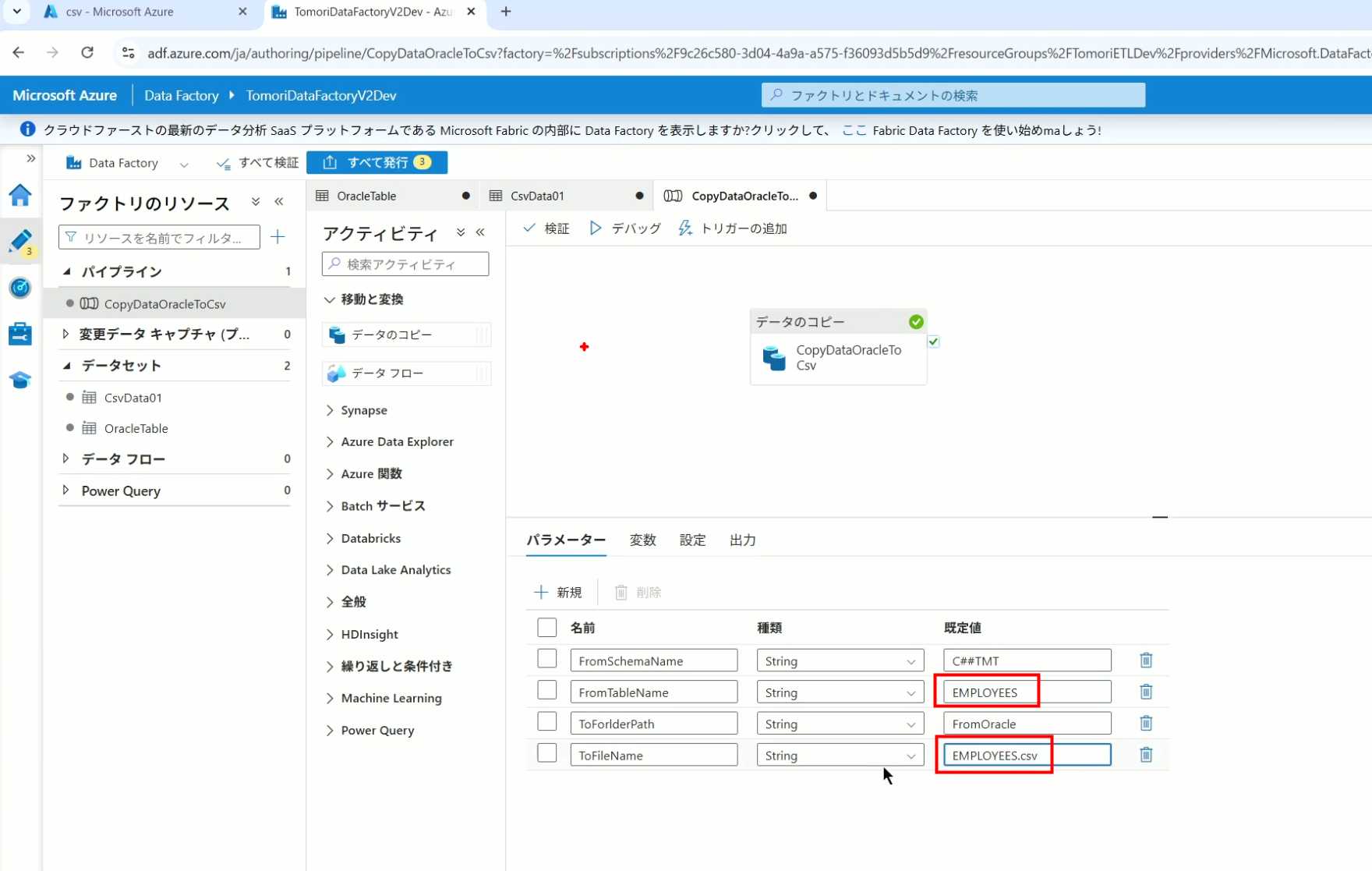
13、转到Storage,可以看到,文件以我们设置的参数值生成了
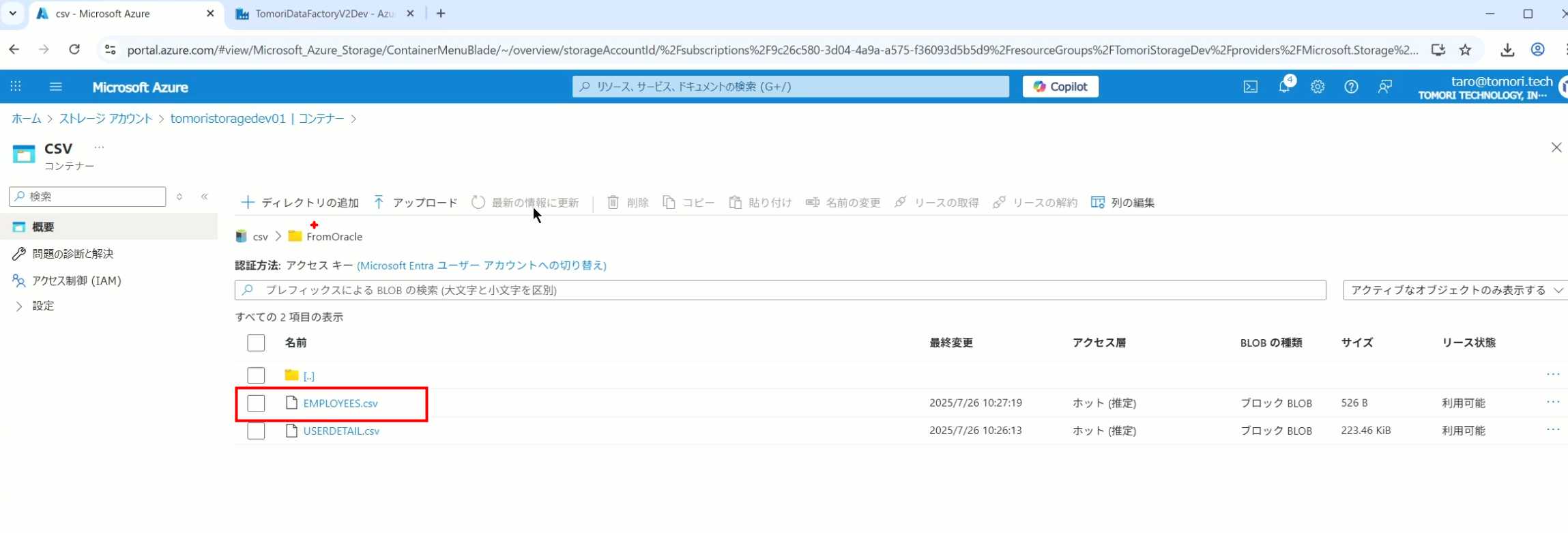
14、揭下来,我们给Pipeline添加一个变量
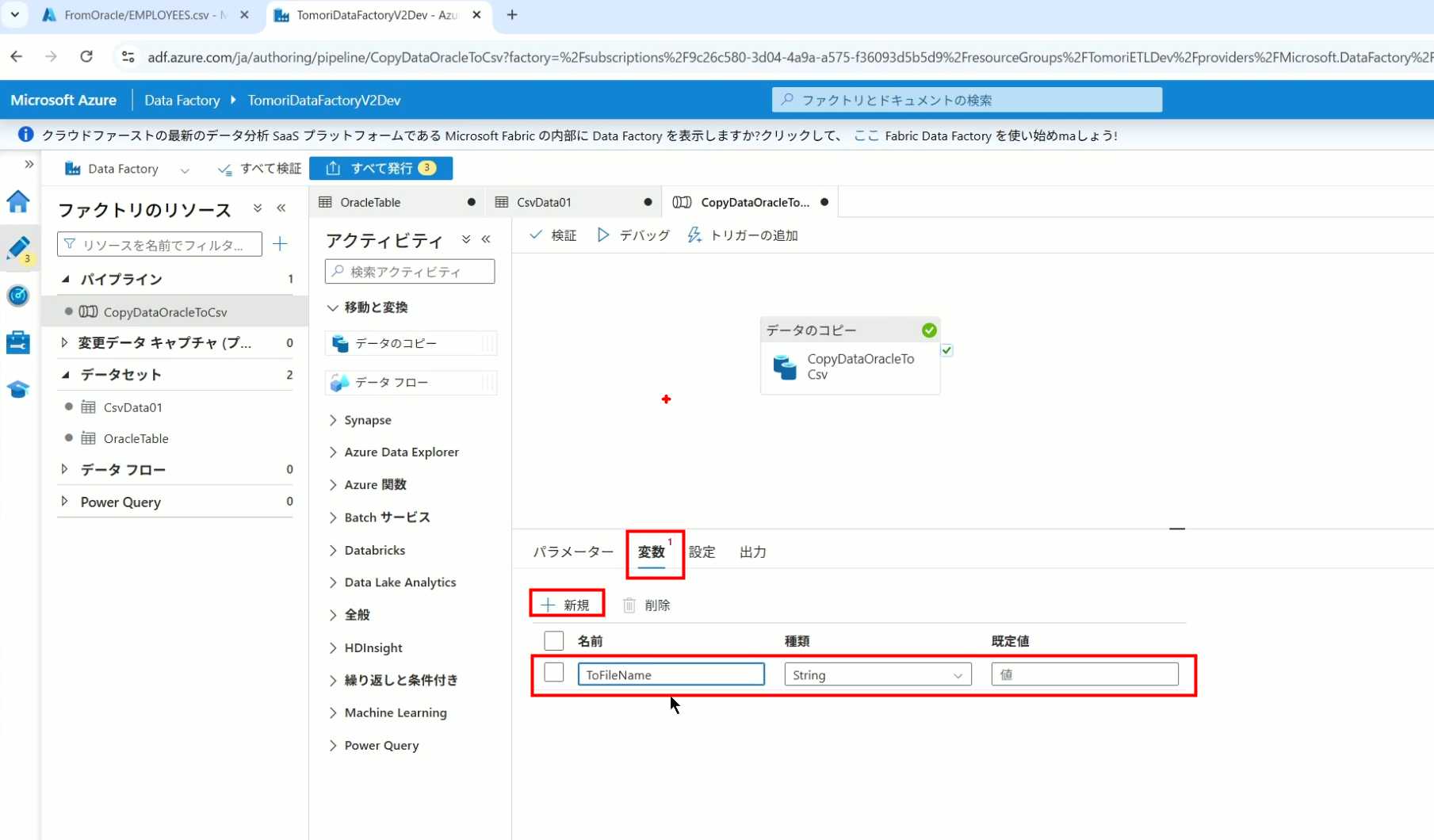
15、从左边的Activity一览里拖入设置变量的Activity
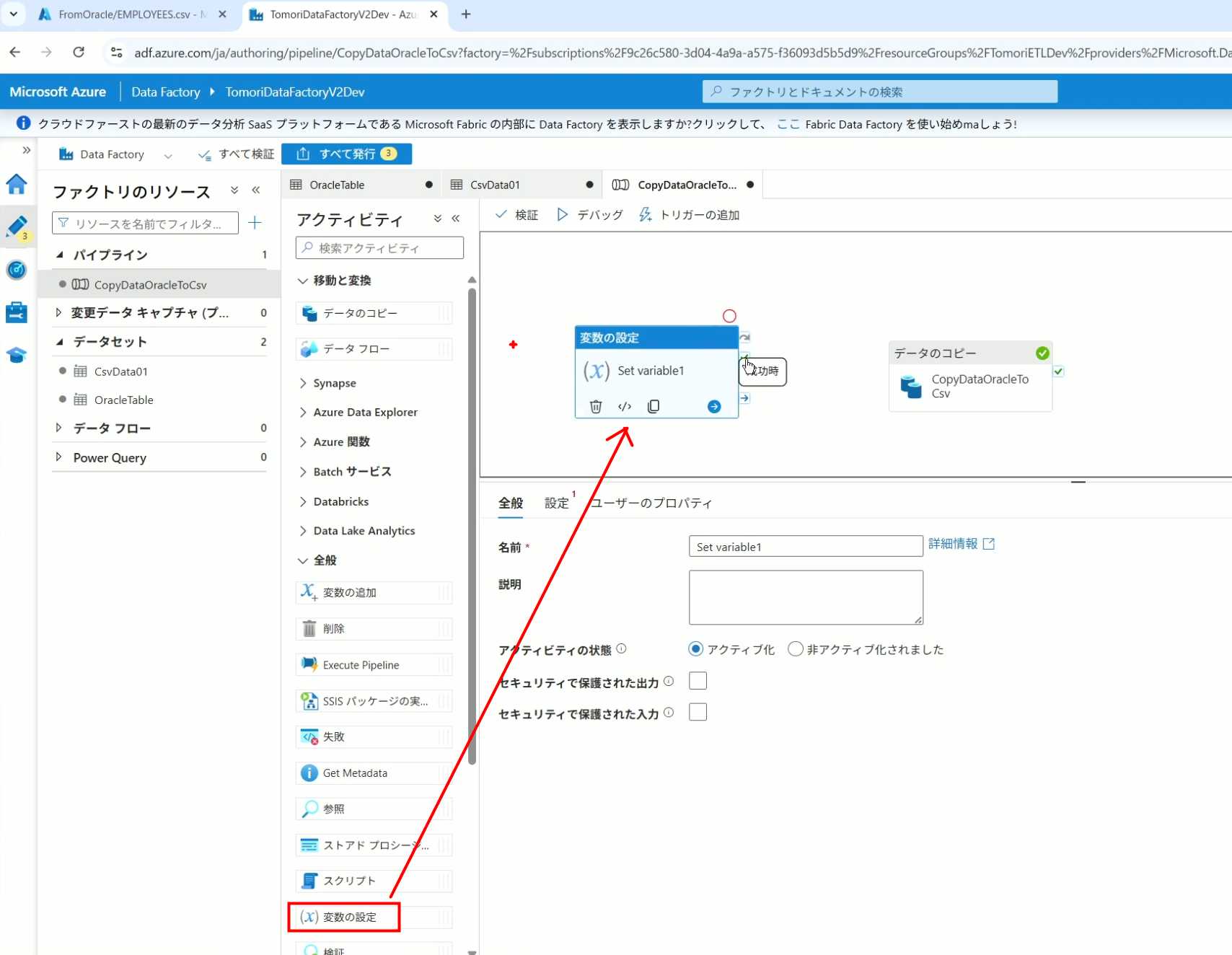
16、将两个Activity用绿线连起来(绿线代表前一个执行成功时,下一个接着执行,红线代表前一个执行失败时,下一个接着执行)
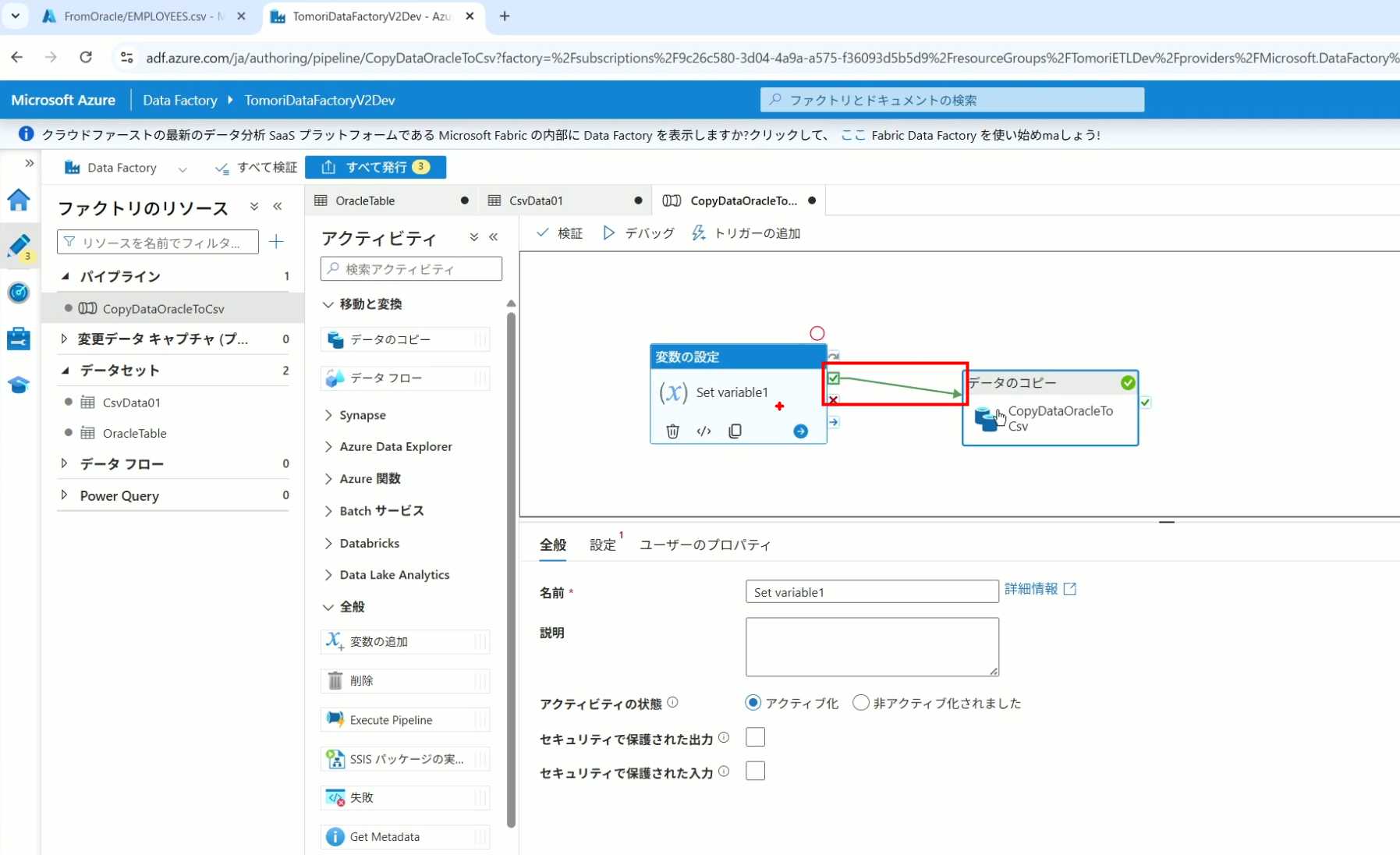
17、对设置变量的Activity进行设置,修改Activity的名字
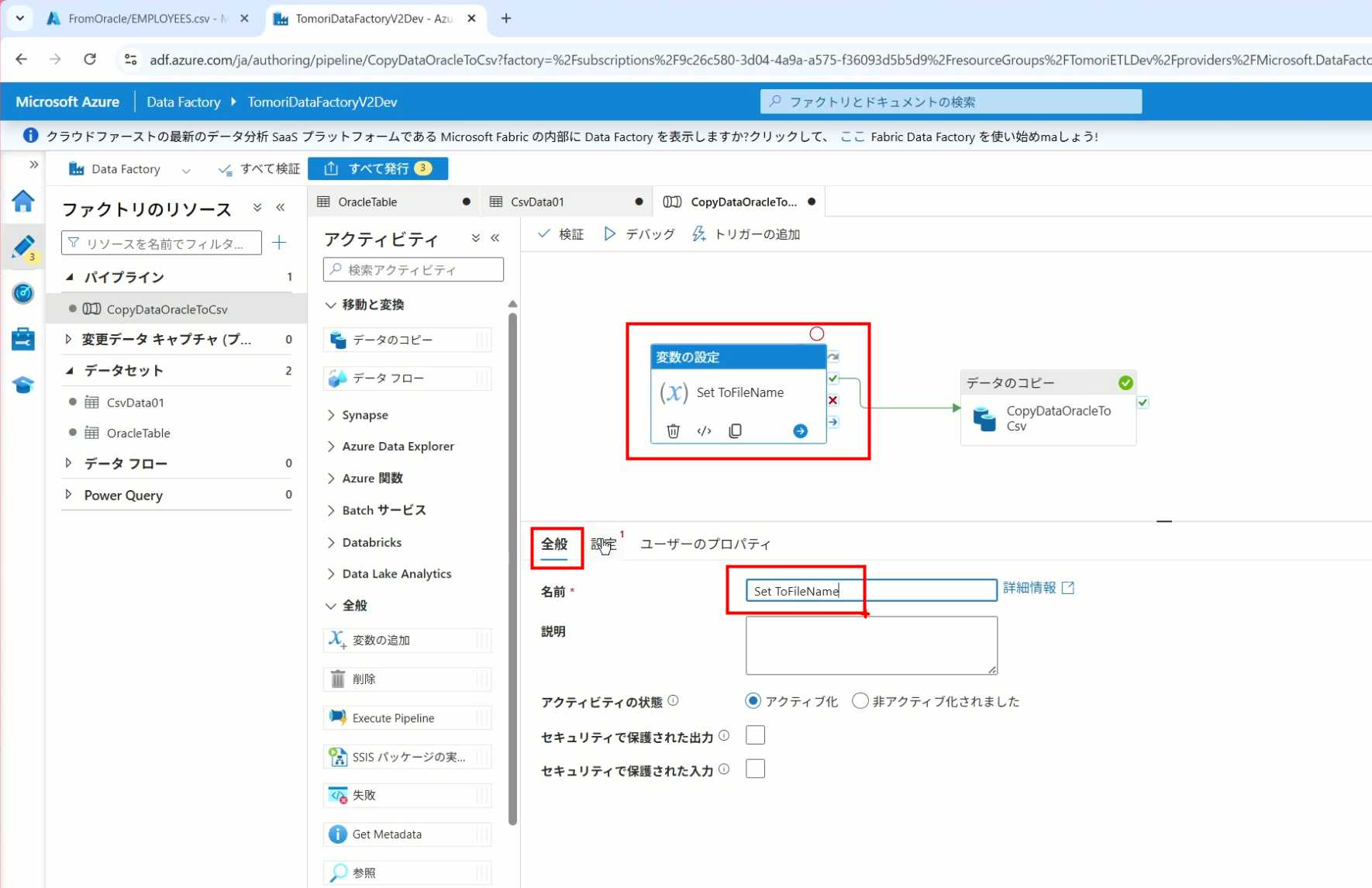
18、对设置变量的Activity进行设置,给变量添加一个值,值可以是手写,也可以选择Pipeline的参数
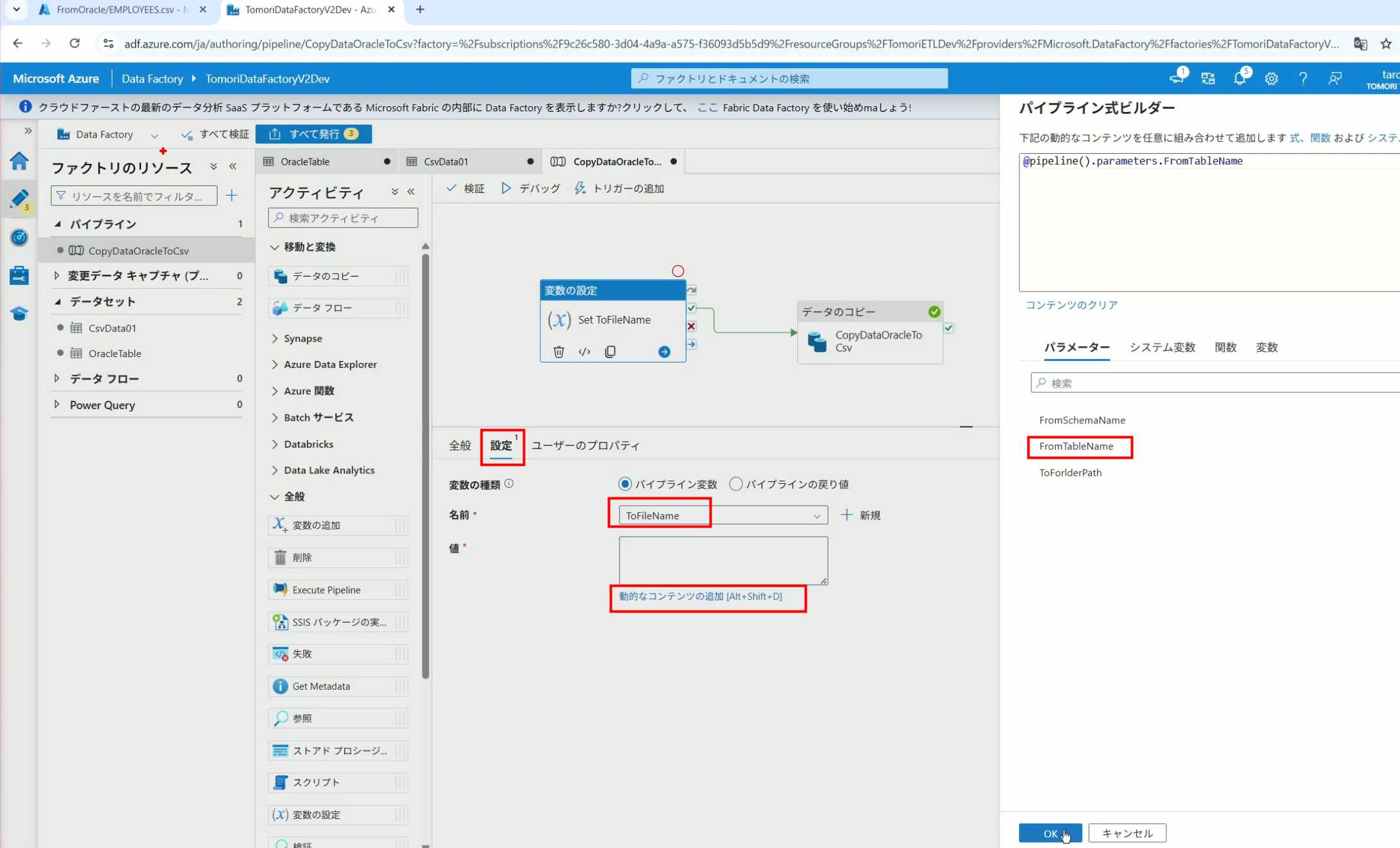
19、当我们想在编辑框里手动编辑时,要符合代码的语法才行,如果不符合语法汇报错,比如想在变量后面加个「.csv」的话,不能直接添加
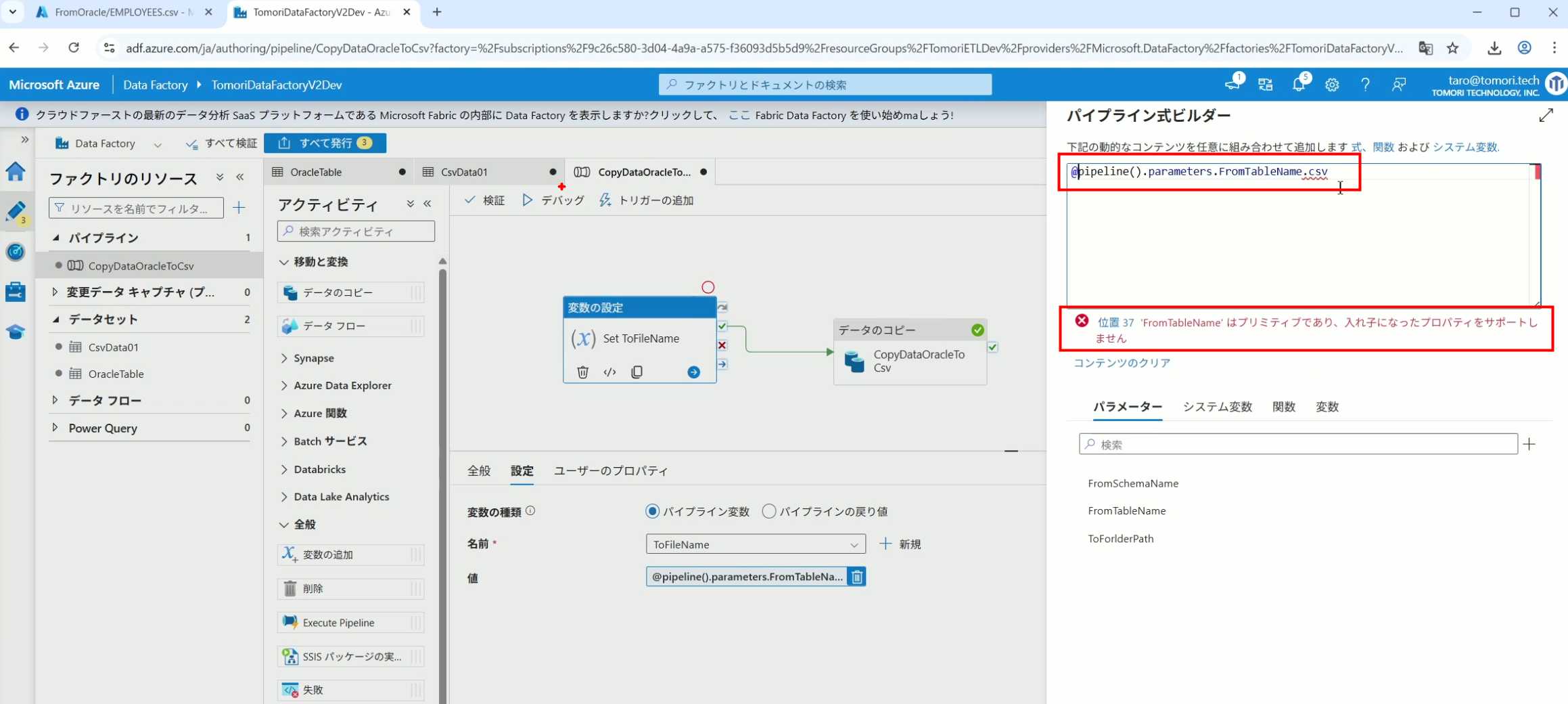
20、在Data Factory提供的函数中,可以选择concat,当鼠标停留在上面时,会显示函数的作用,concat是将多个字符串连接到一起
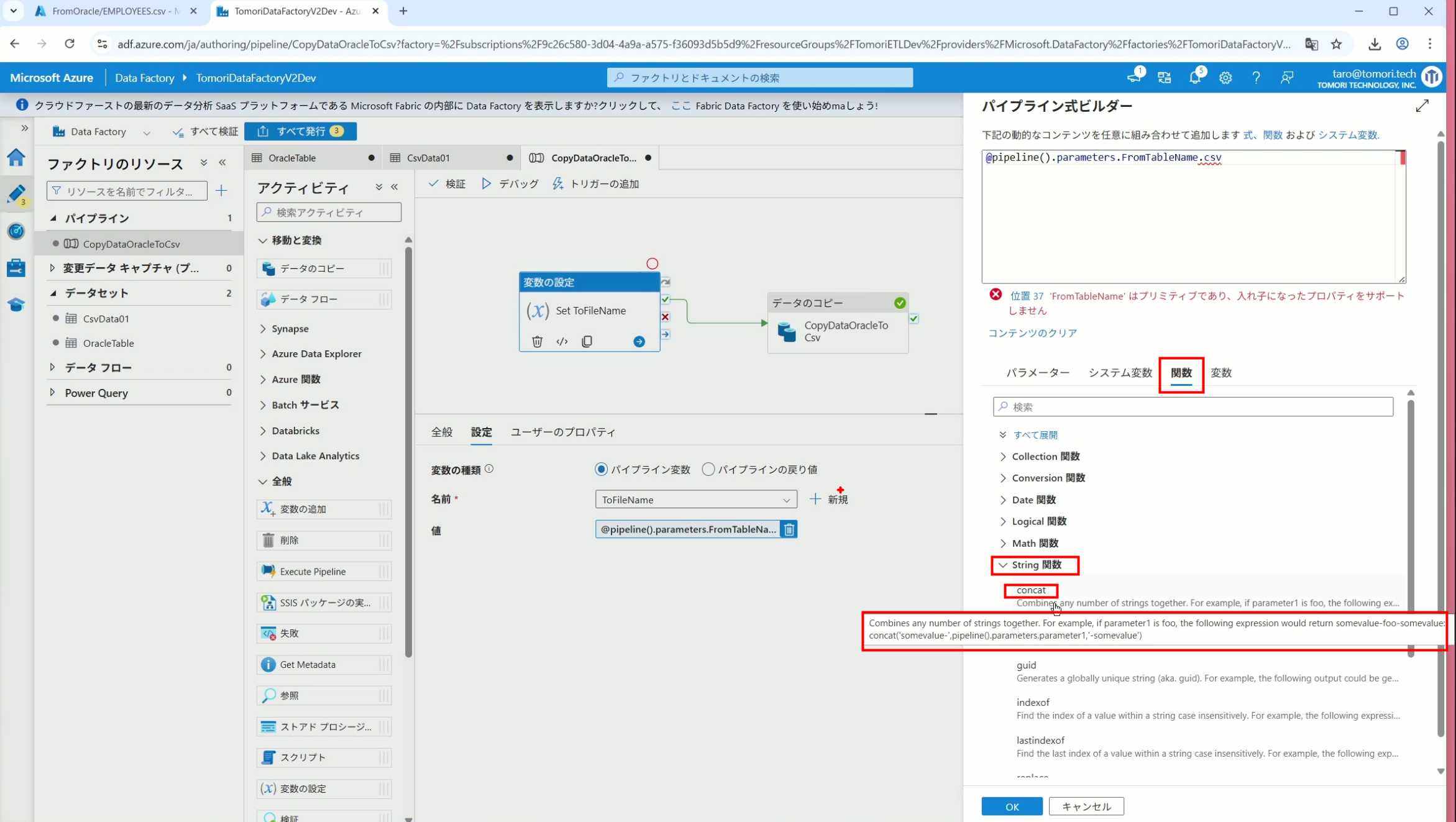
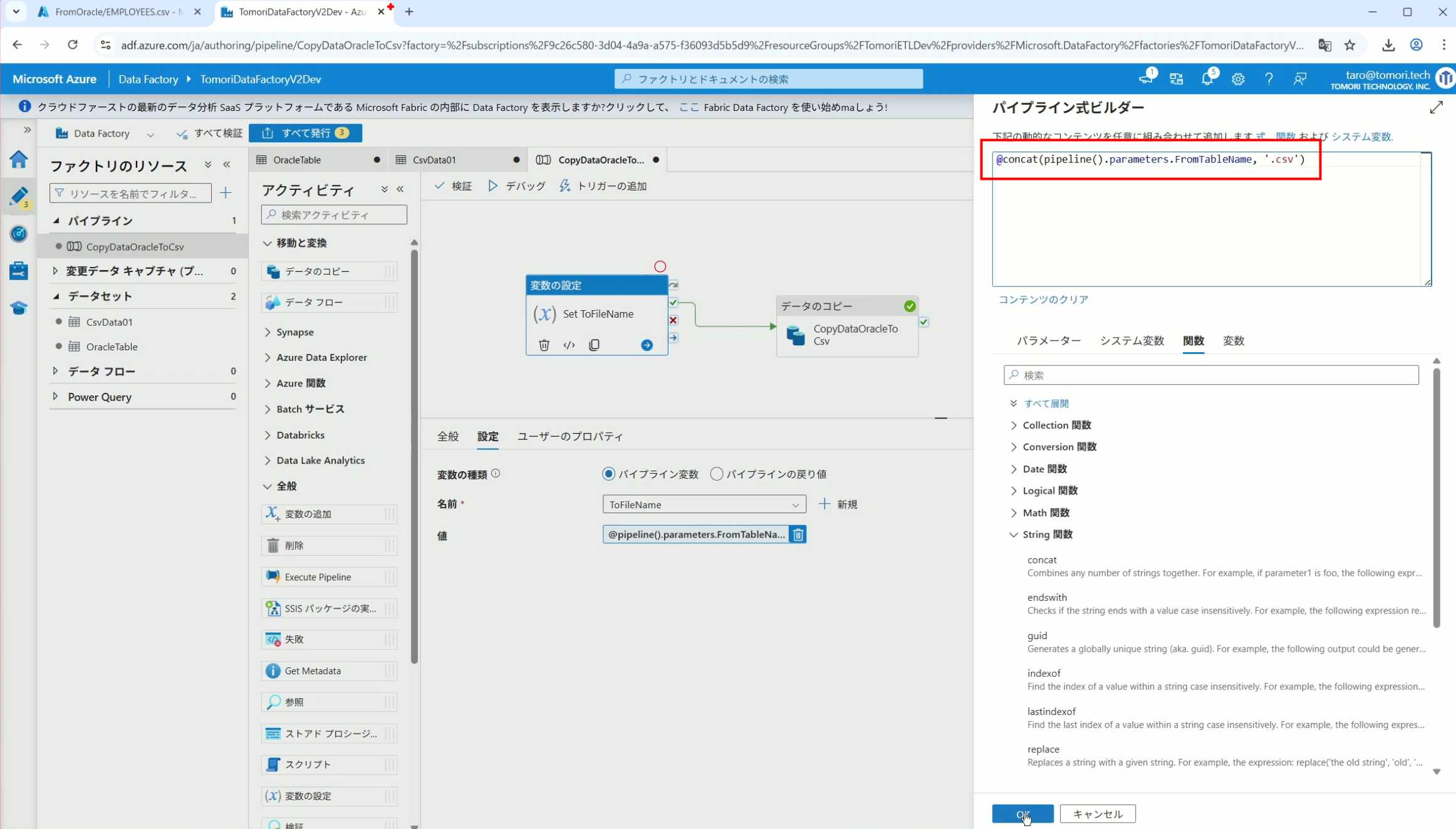
21、使用了concat之后的设置(符合语法,不会报错)
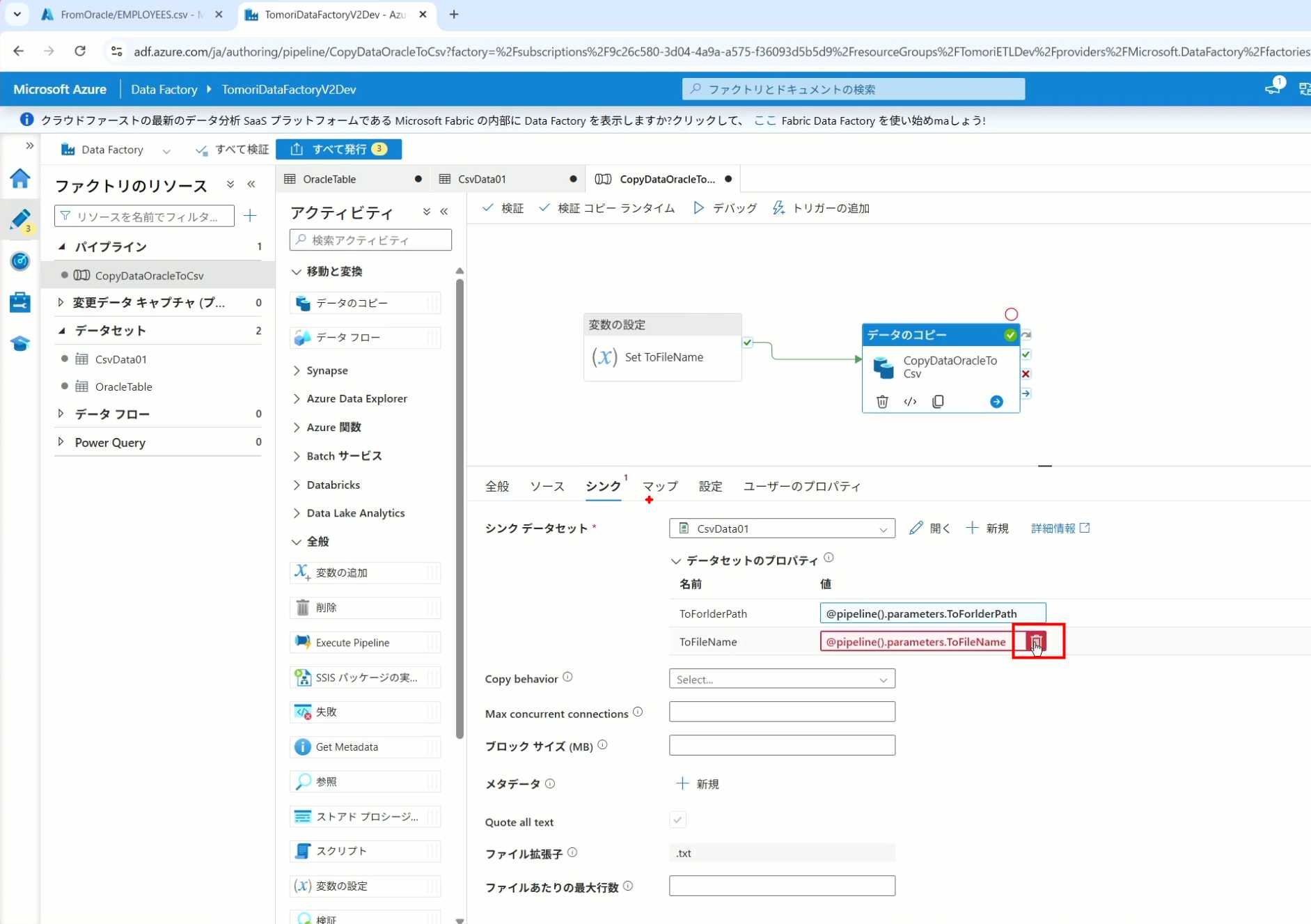
22、比如我们可以将Sink的文件名删掉
23、改用变量
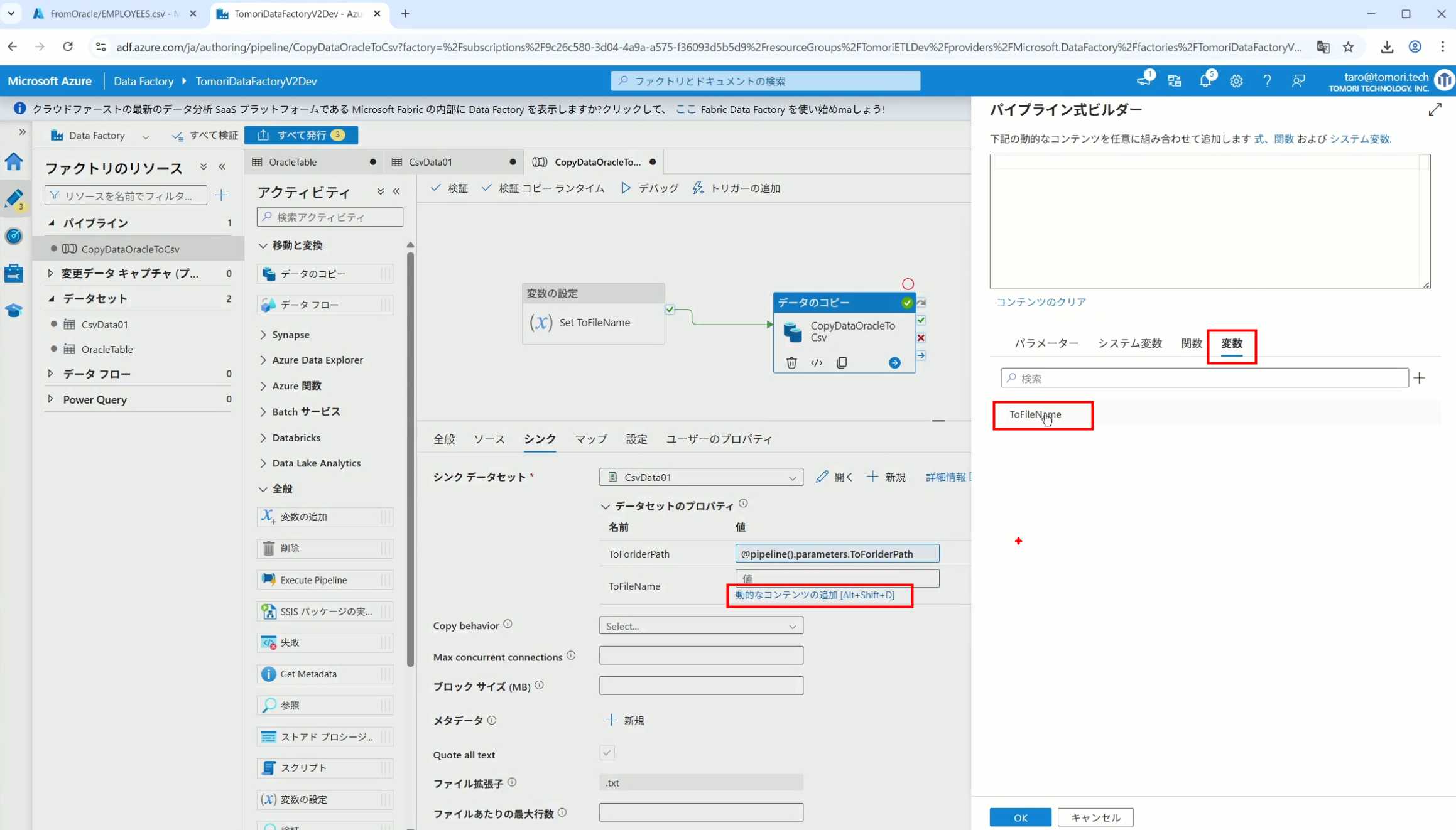
24、设置好使用变量的样子
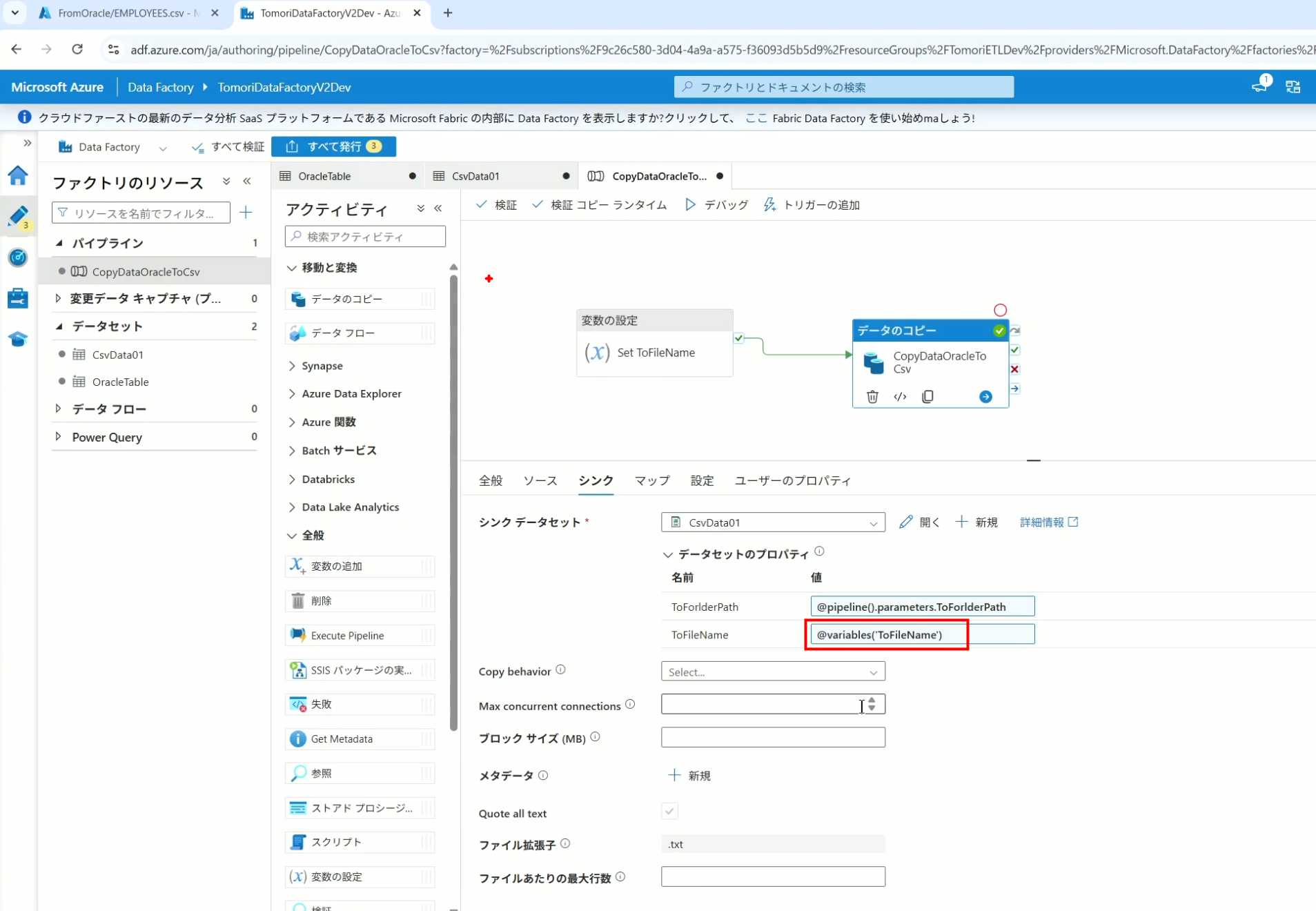
25、还可以对文件名进行编辑,比如加一个时间后缀,这里选择使用utcNow函数和formatDataTime函数,将当前时间转换为yyyyMMddHHmmss格式
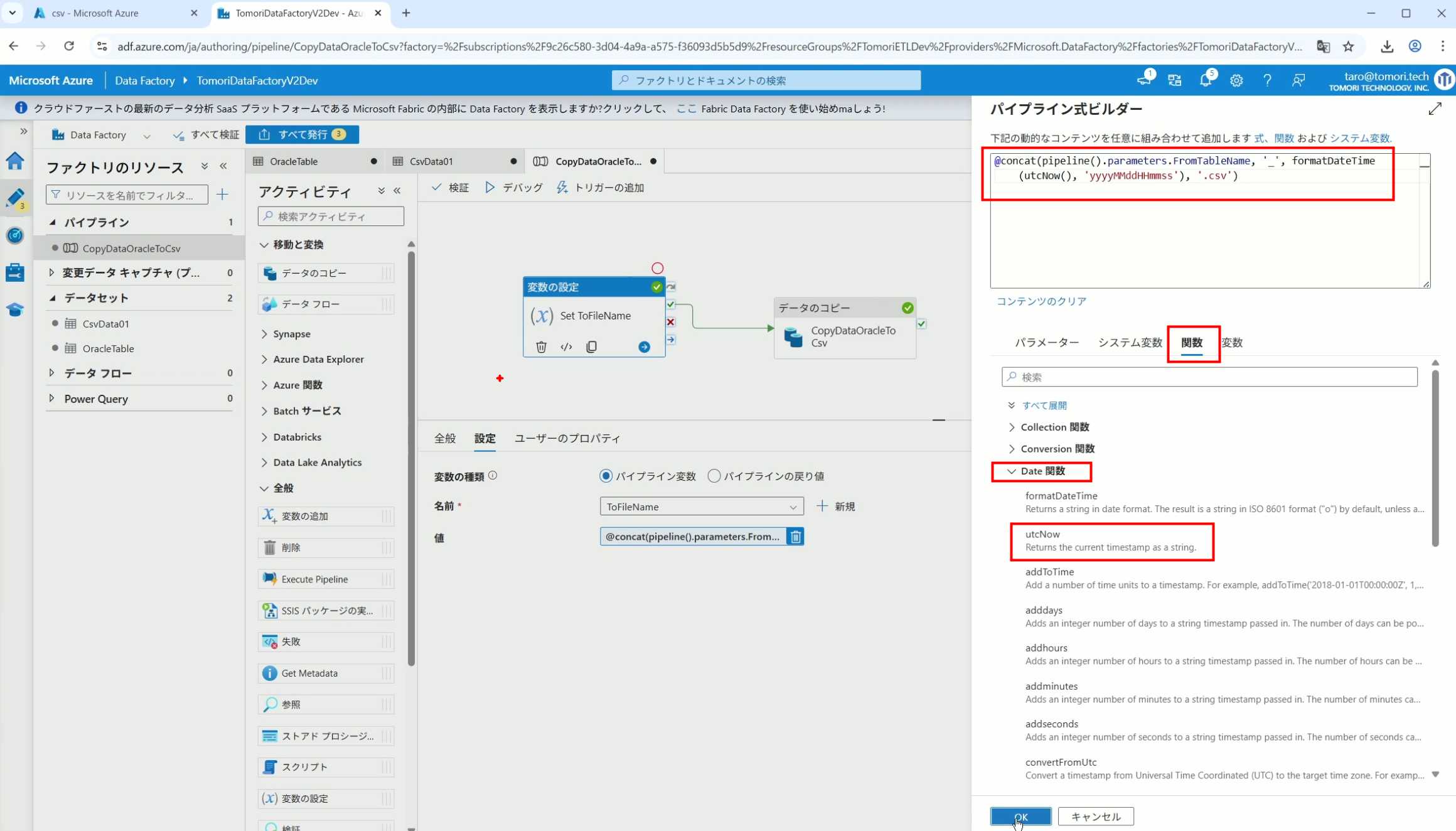
26、再次执行Pipeline,执行成功后,在Storage里可以看到,文件以带有时间后缀的形式生成了
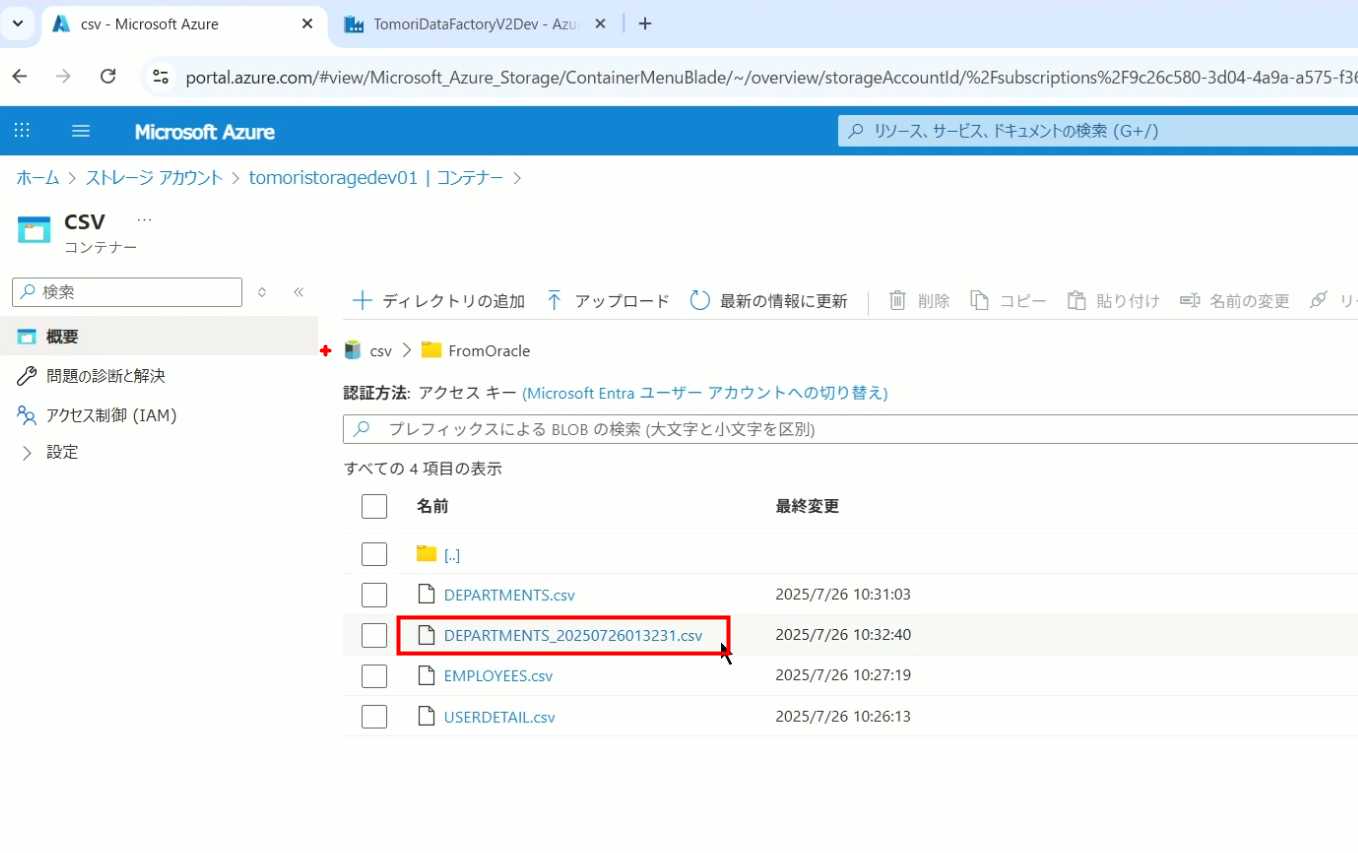
27、也可以使用convertTimeZone函数,将当前utc时间转换为日本时间
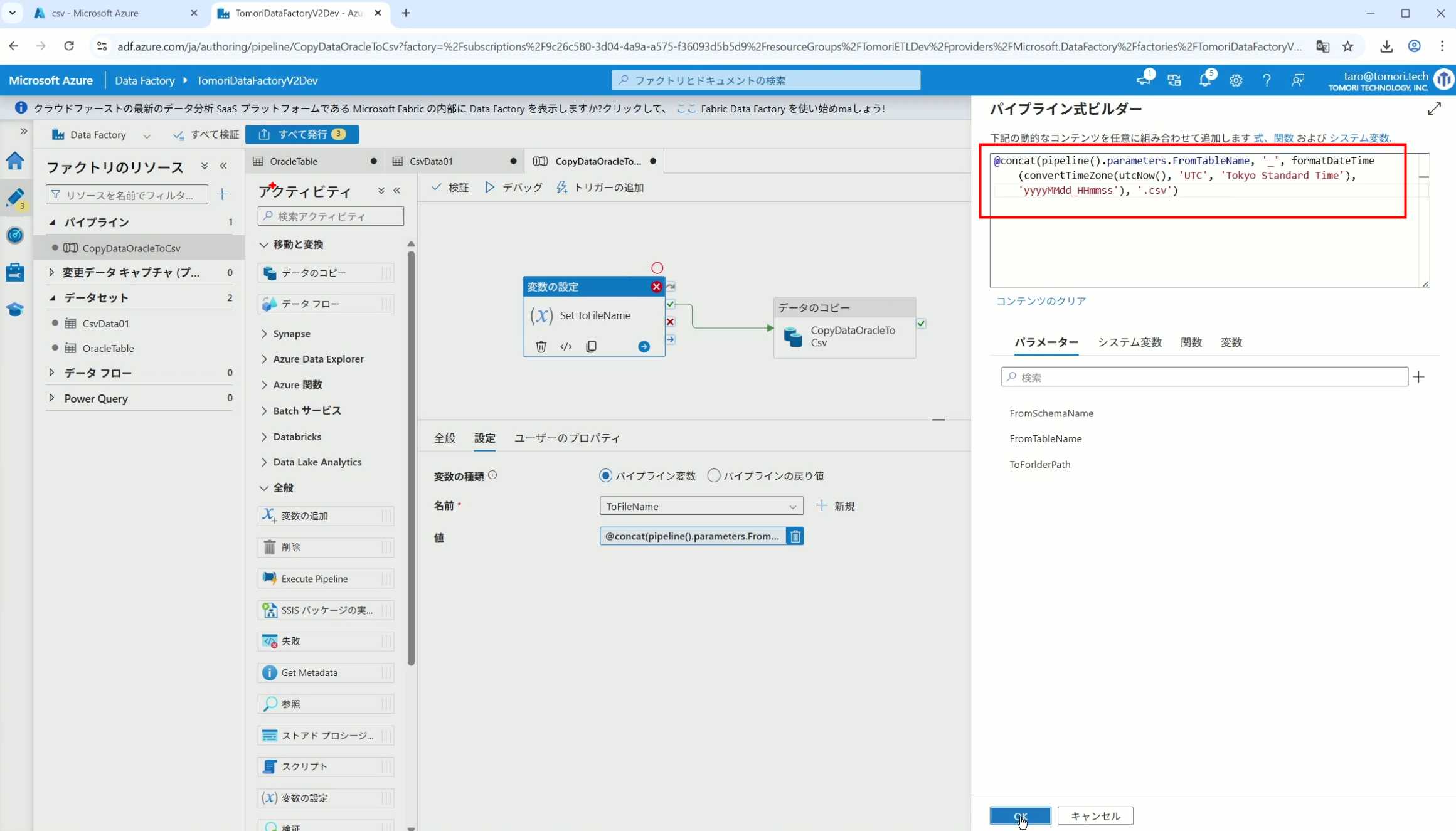
28、再次执行Pipeline,执行成功后,在Storage里可以看到,文件以带有时间后缀的形式生成了,并且时间是日本时间
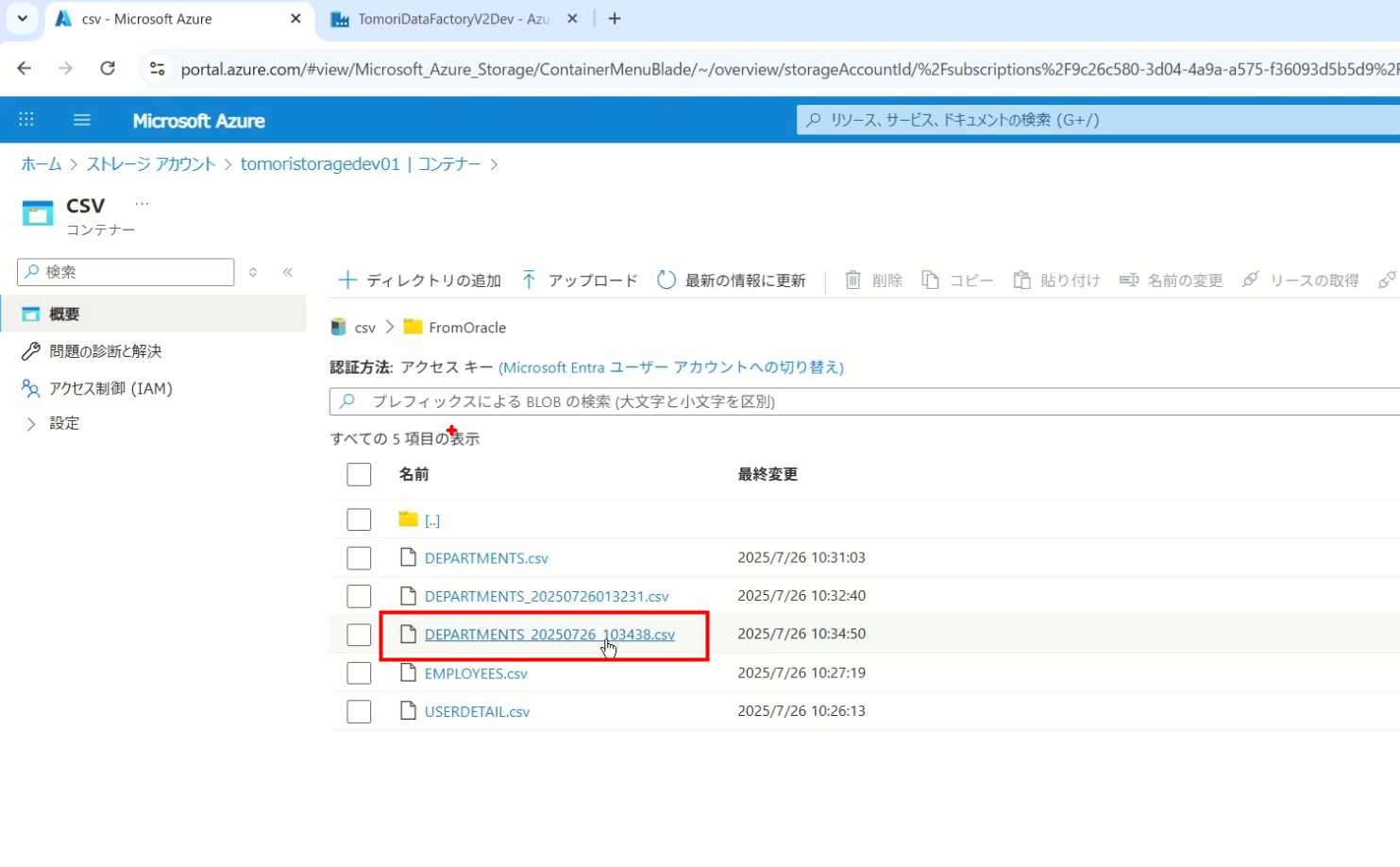
29、发行Pipeline
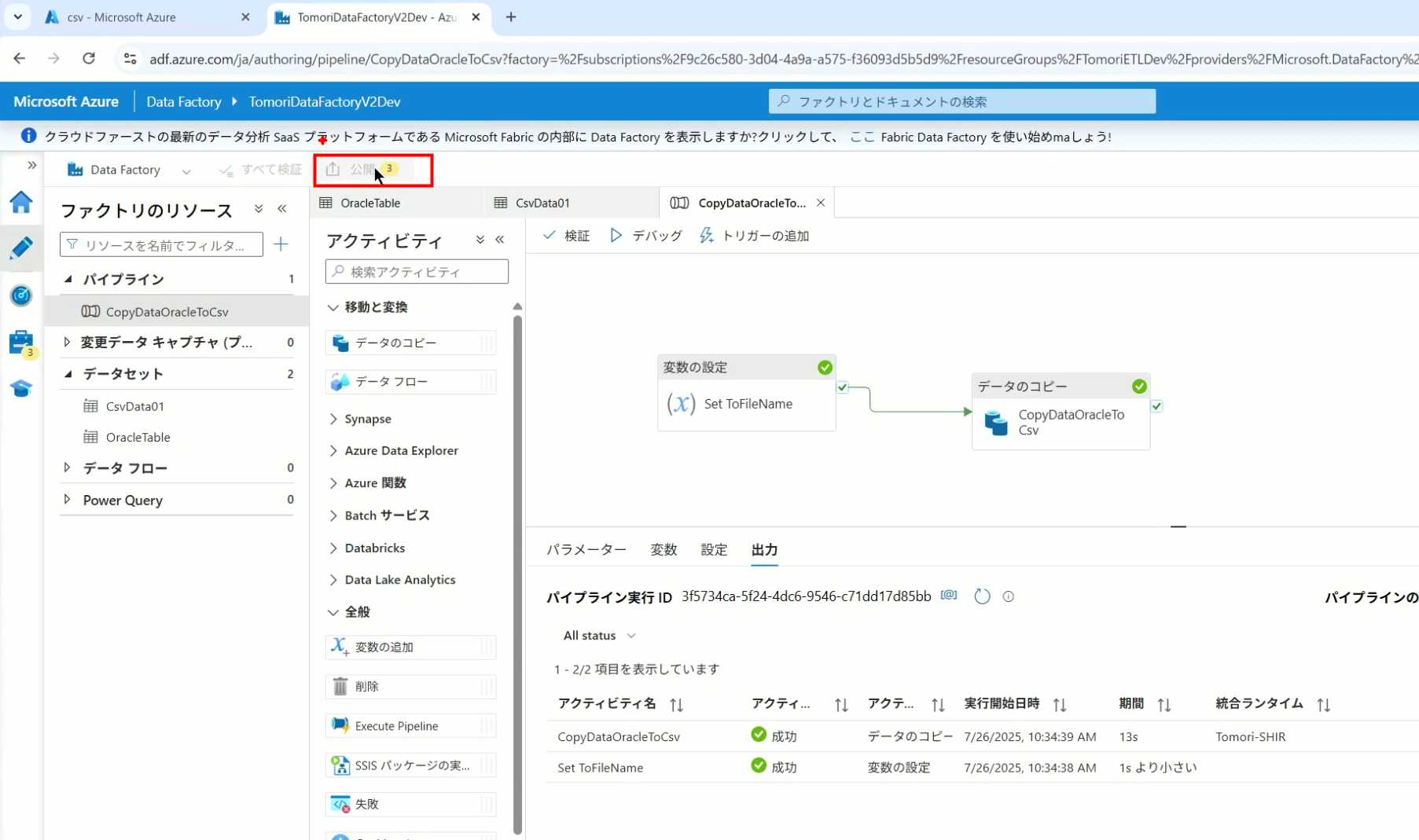
30、确认Pipeline的修改点,没有问题的话点击发行
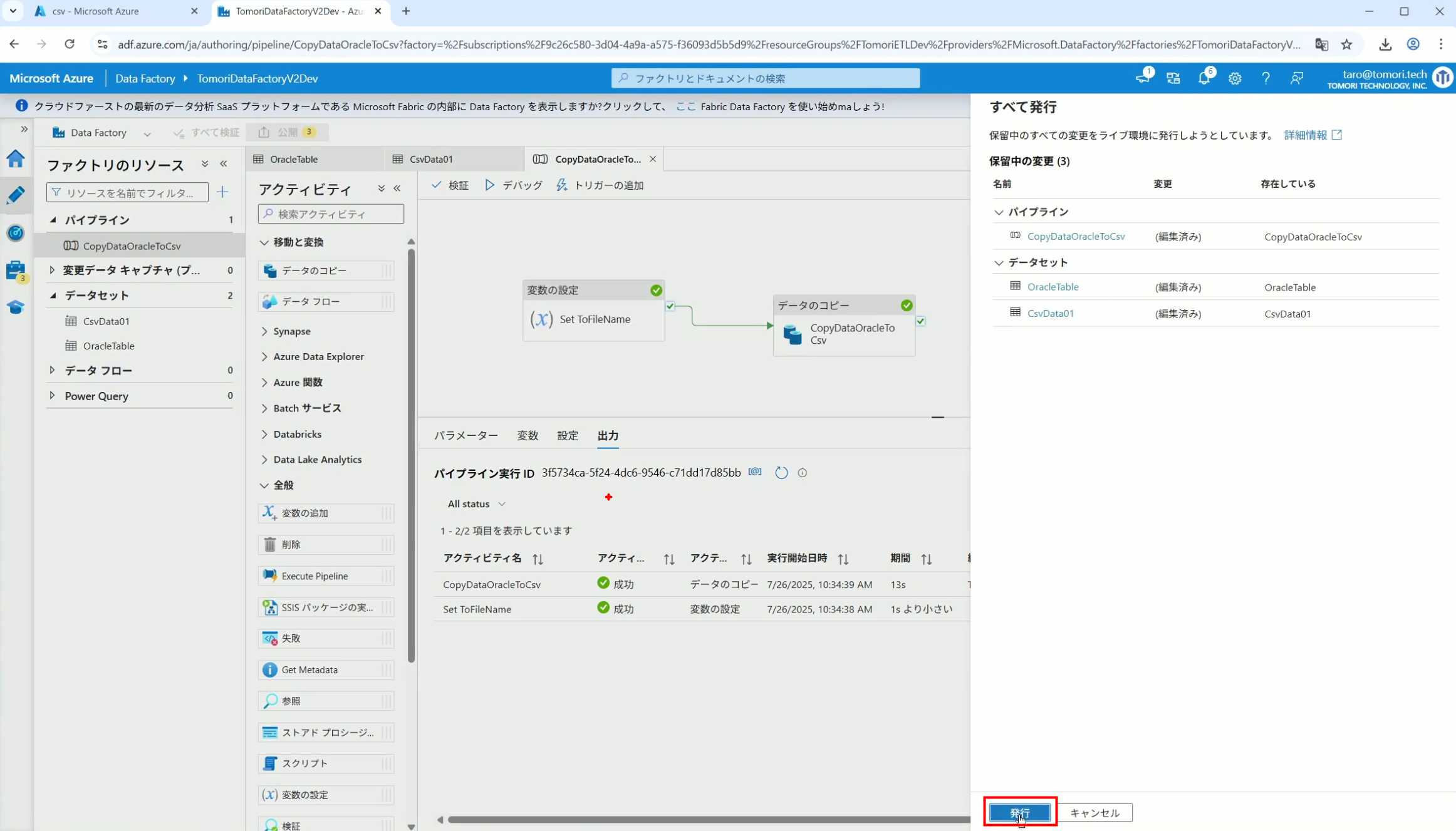
31、按照图示,可以点击Trigger执行→马上Trigger
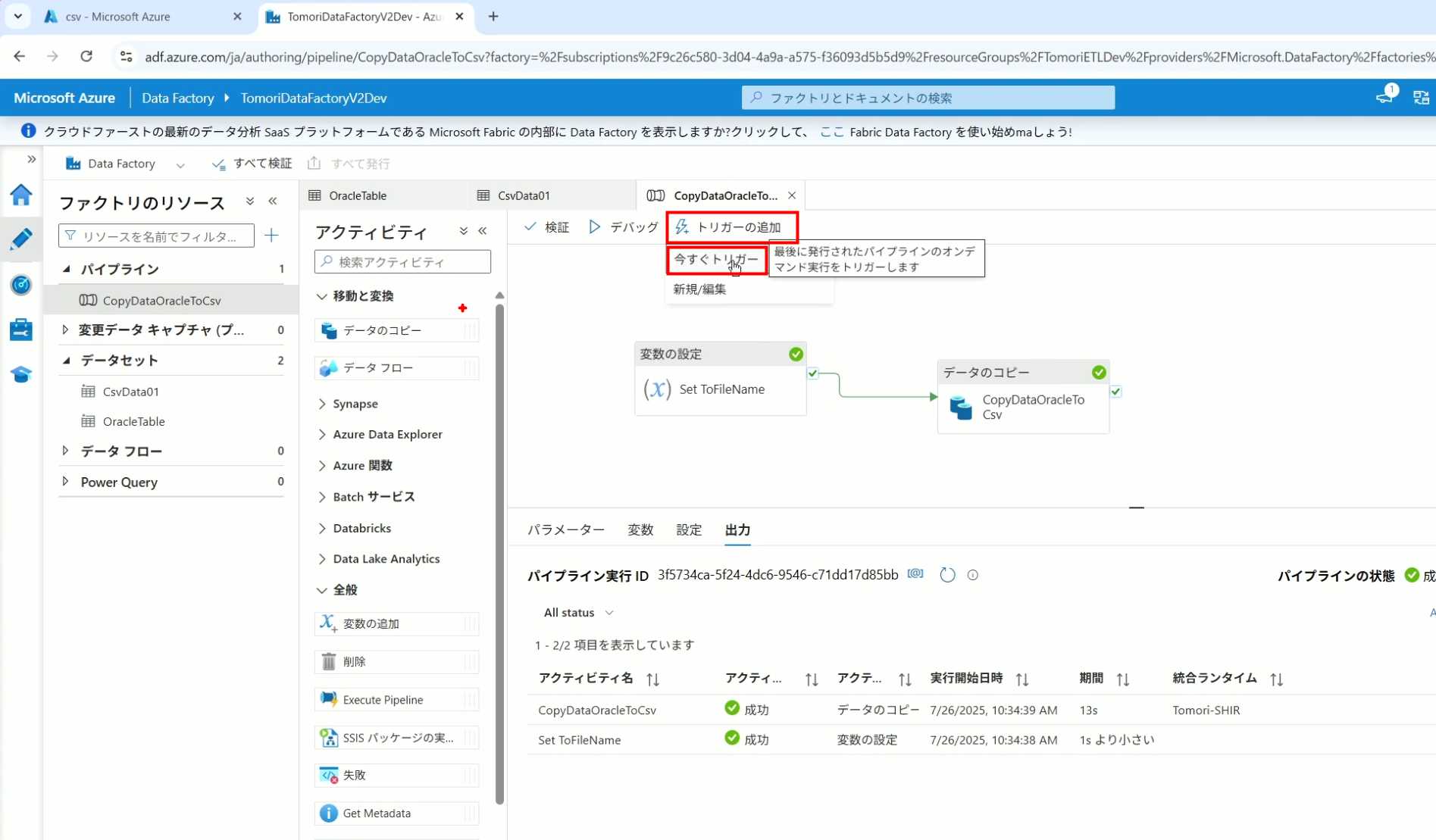
32、弹出参数框,因为设置了默认参数,这里不需要再设置,点击OK
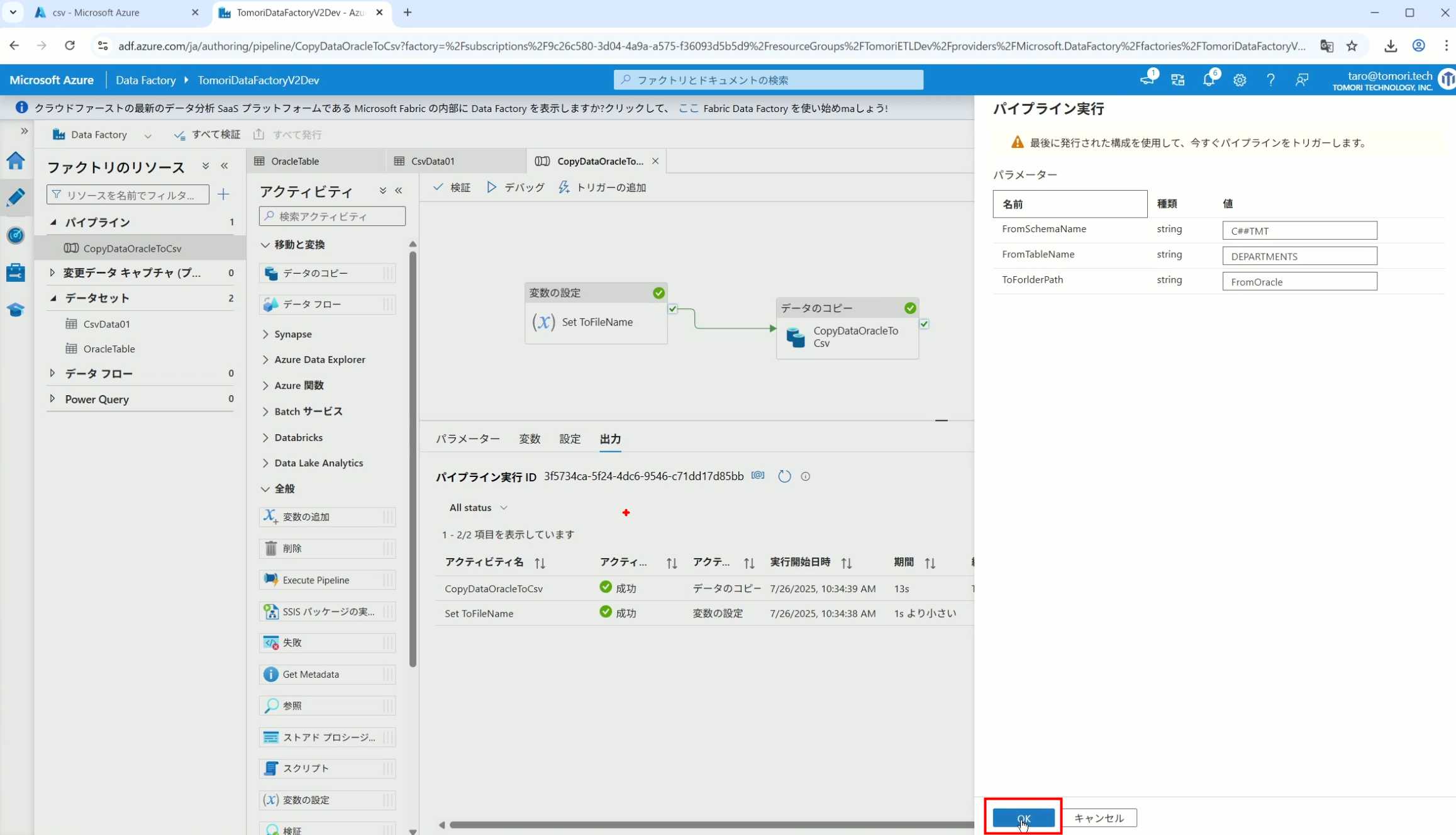
33、转到监视界面,可以看到Trigger执行的执行结果
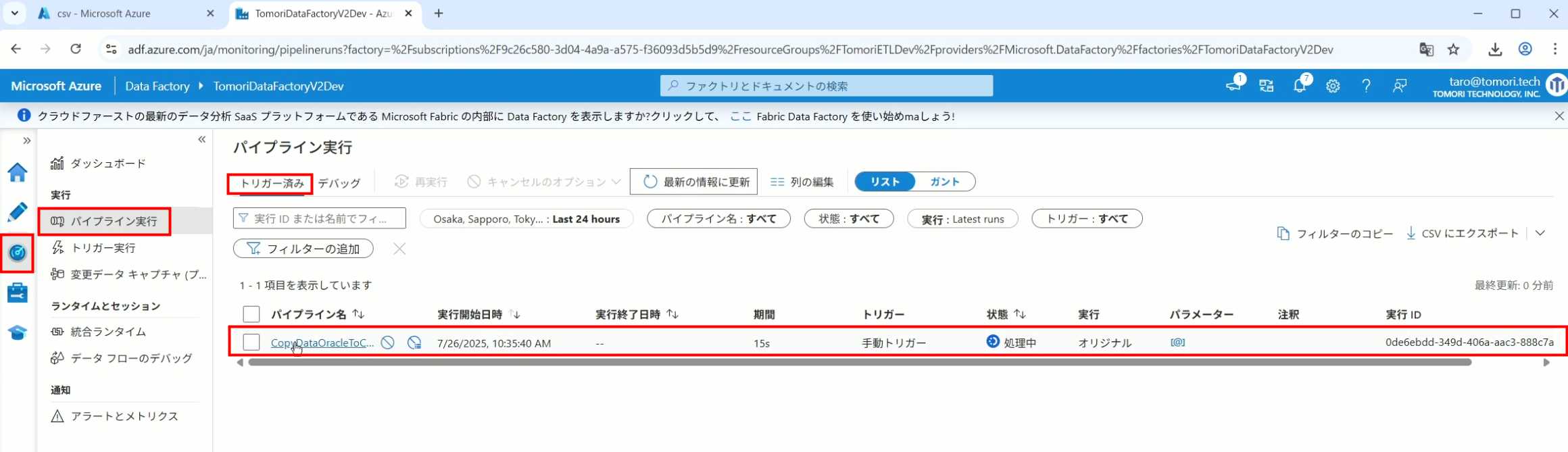
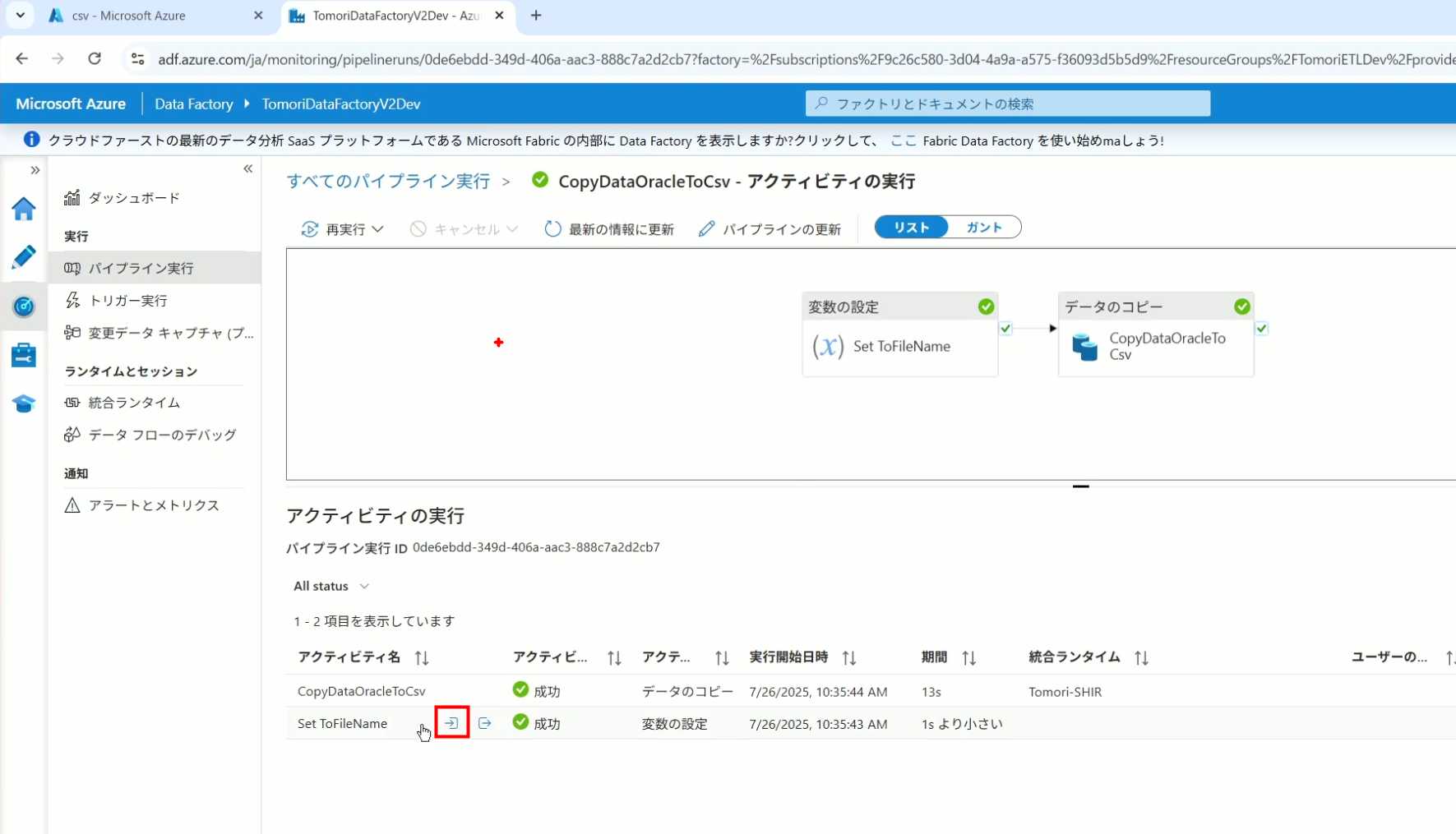
34、点击Pipeline,进入到详细结果界面,可以查看Activity的输入和输出,比如点击输入按钮
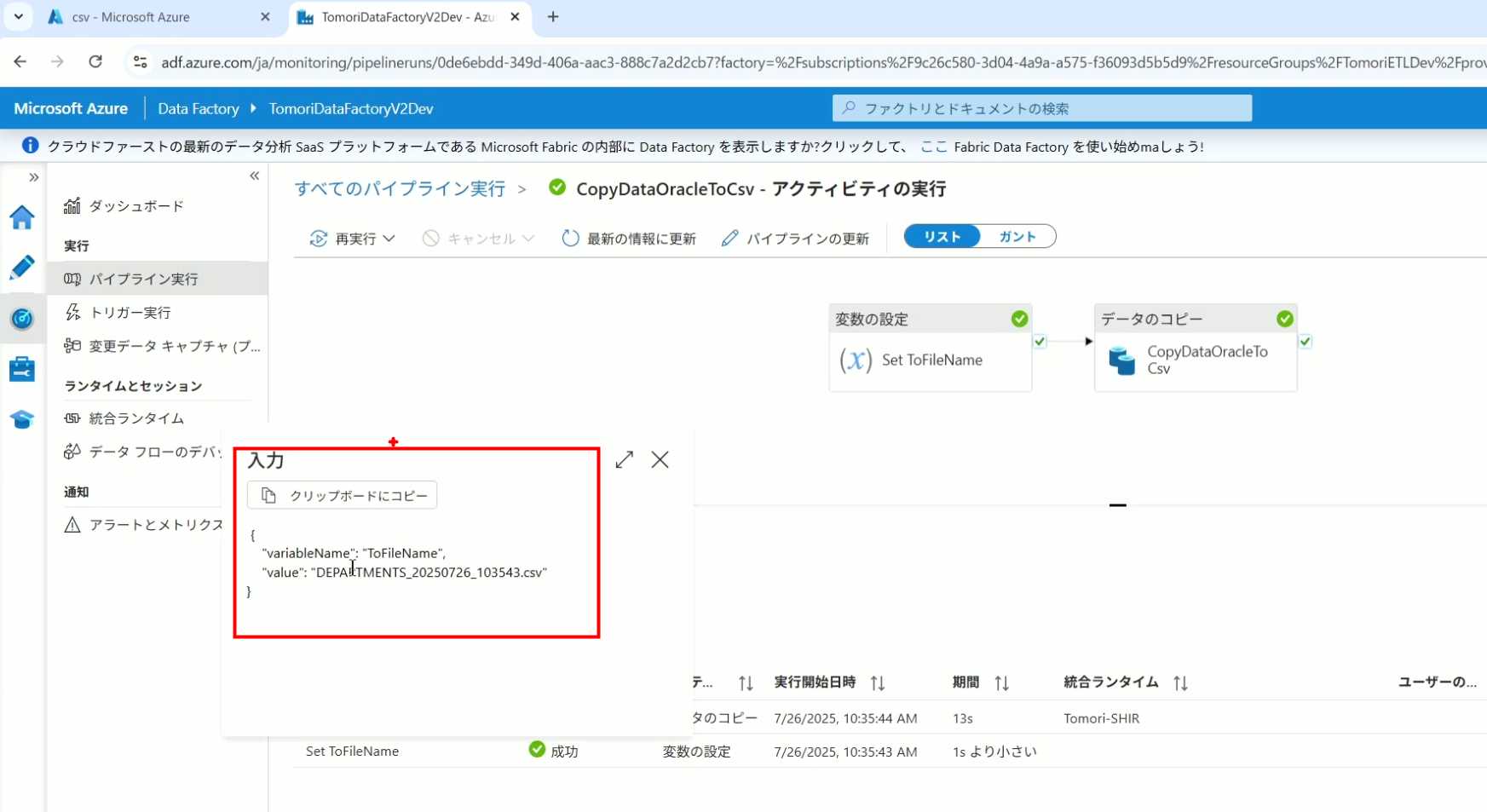
35、可以看到输入的参数
36、点击输出按钮
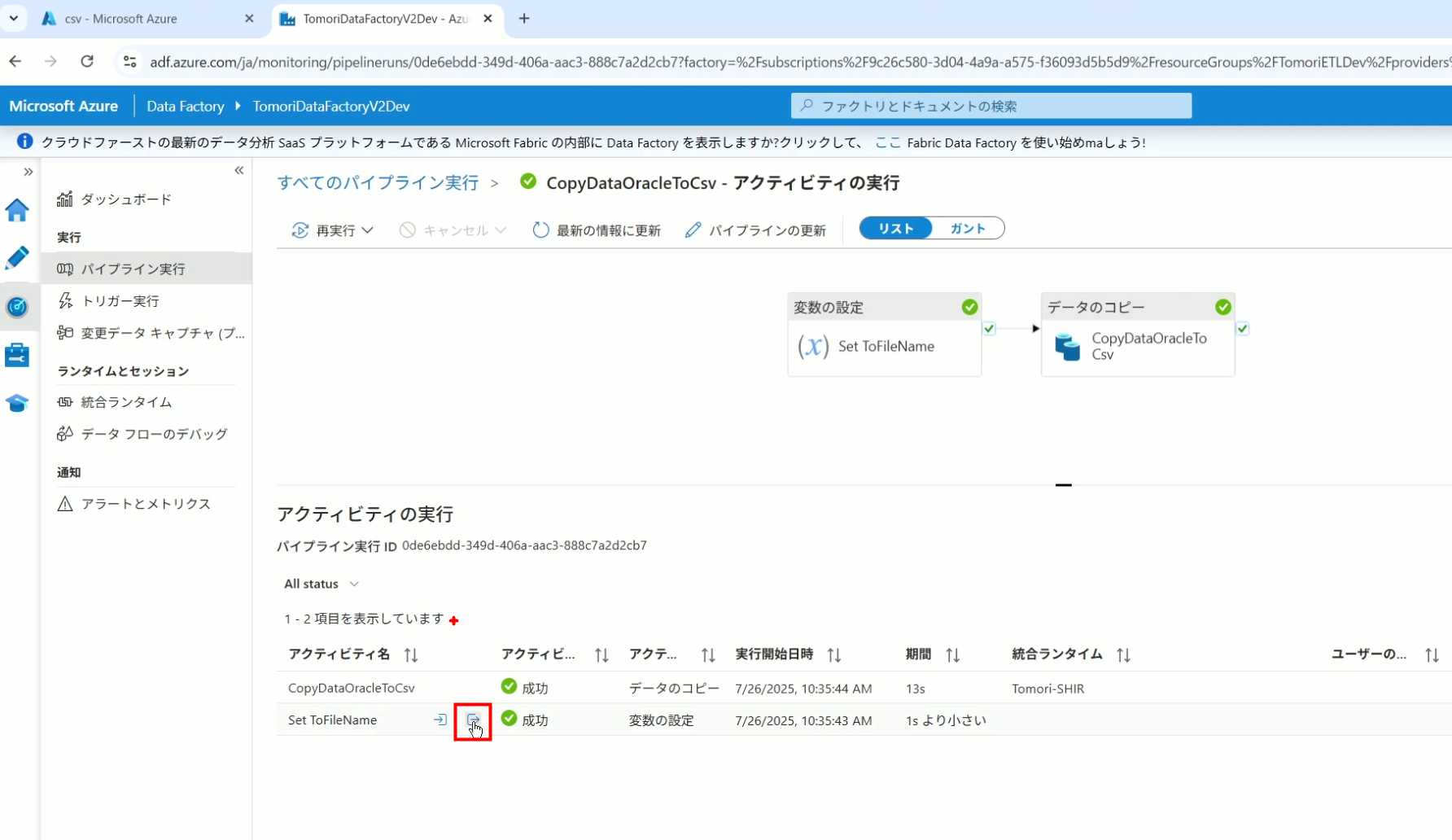
37、可以查看输出的参数
38、在Copy Activity中,有一个眼镜按钮,点击眼镜按钮
39、可以查看数据复制的详细信息,读了多少行,读了多少Size,写了多少Size,用时多少等等
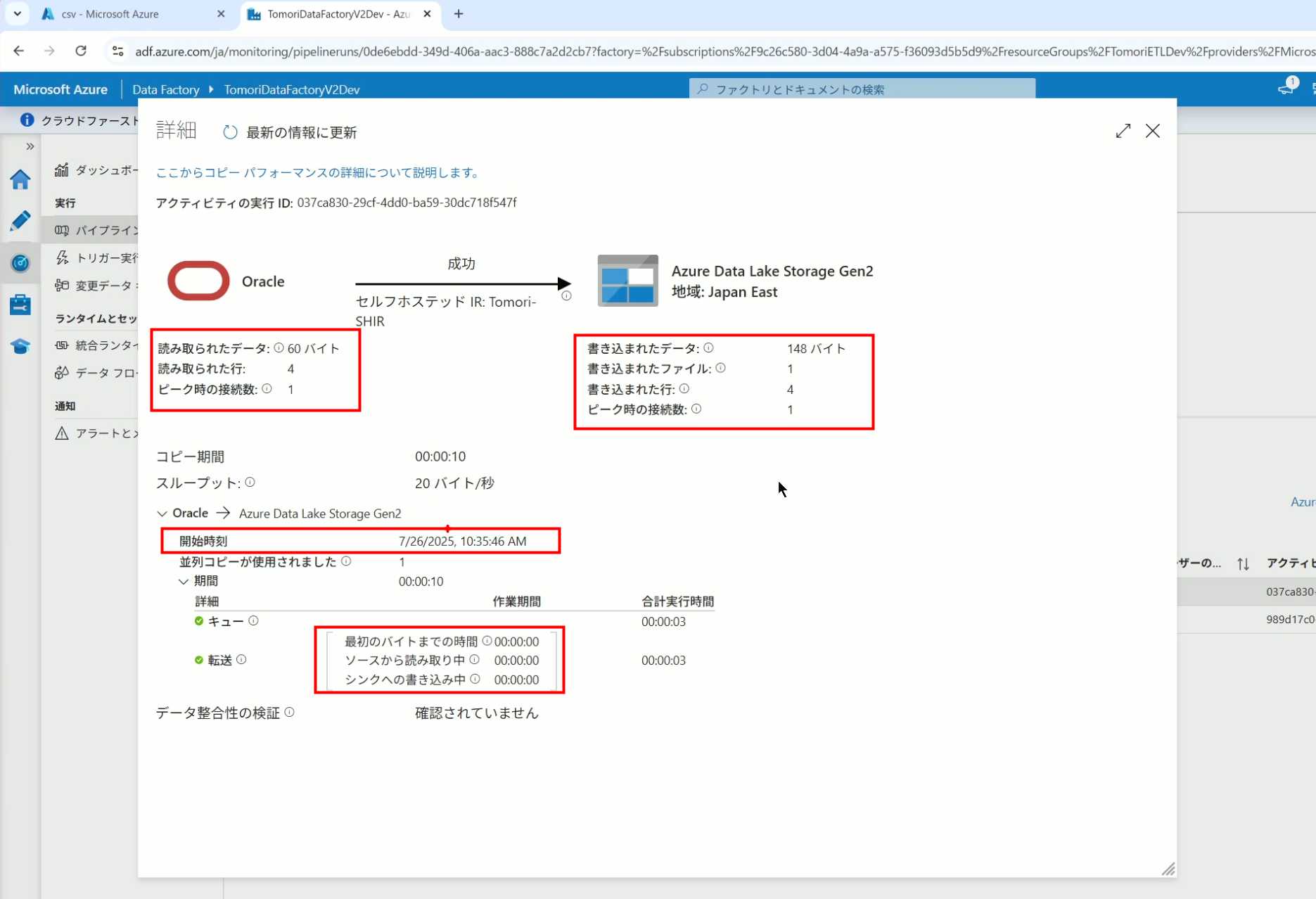
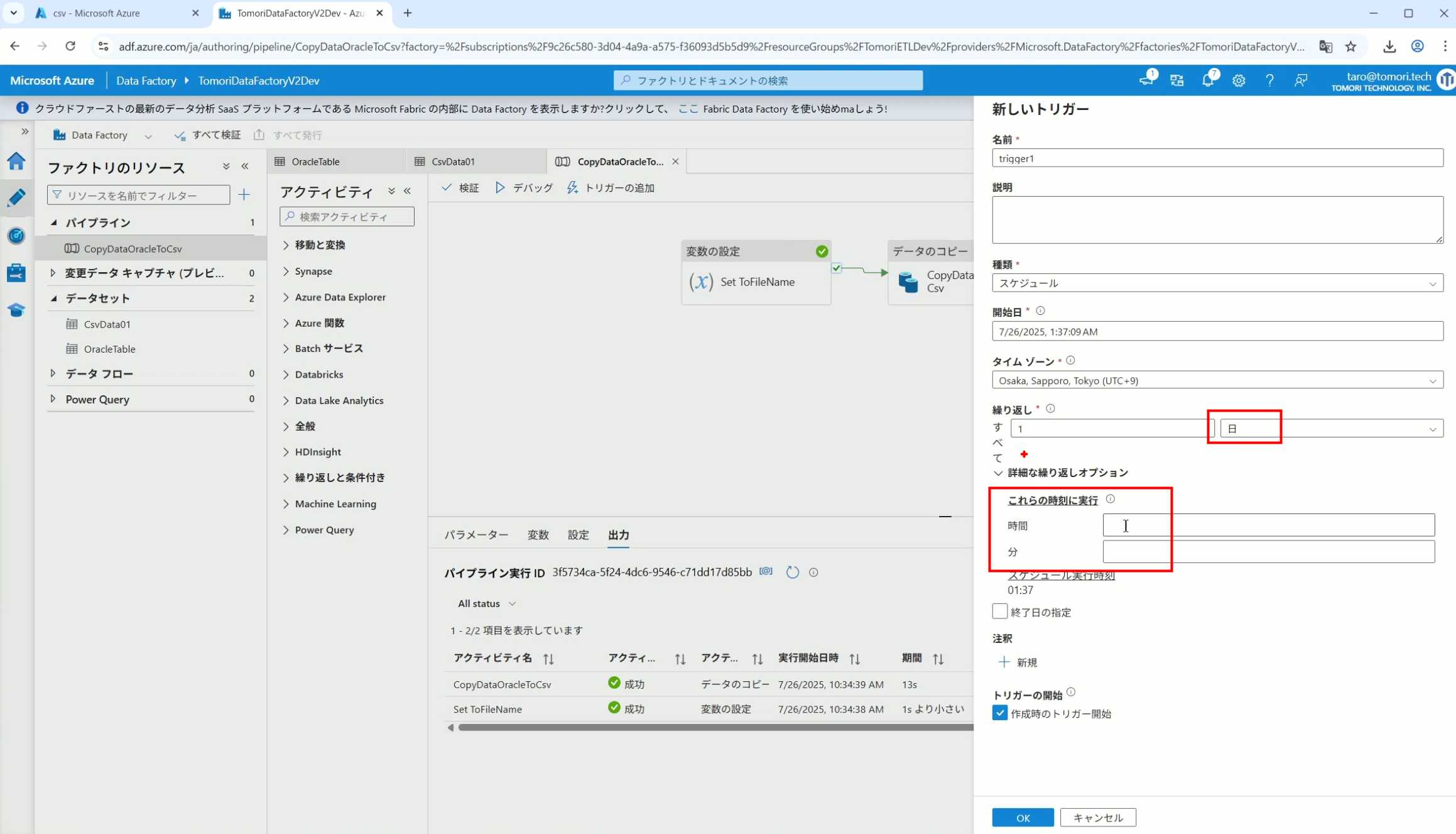
40、在Trigger执行中,还可以设置定期的自动执行
41、选择新建
42、可以选择按天,按小时,按分钟执行等
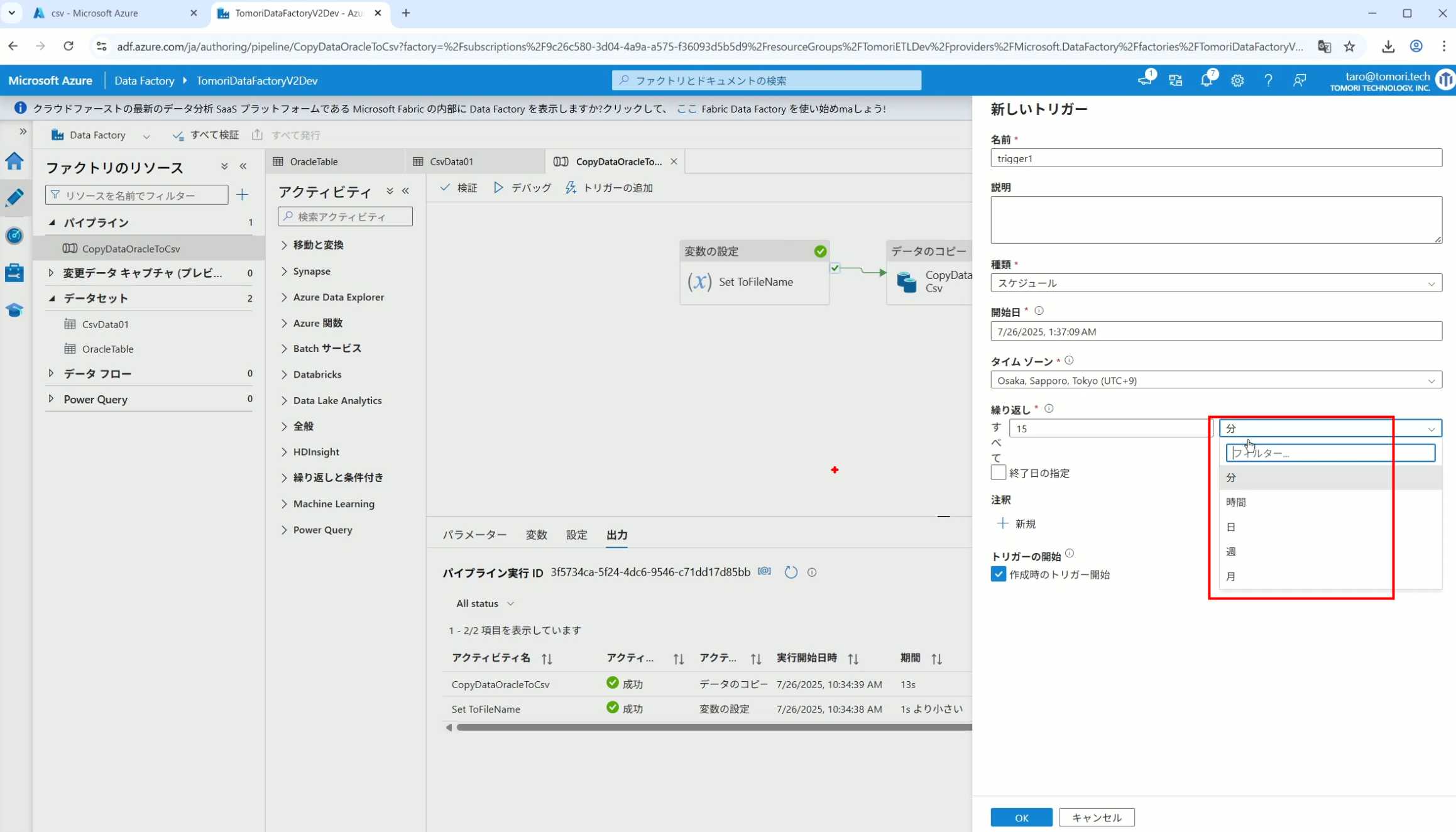
43、比如选择了按天的话,可以设置每天固定的时间自动执行